做网站较好的框架推广普通话手抄报内容50字
现在越来越多的网站已经能够通过JA3或者其他指纹信息,来识别你是不是爬虫了。传统的方式比如换UA,加代理是没有任何意义了,所以这个时候我们就需要使用到curl_cffi 了。
1.TLS 指纹是啥?
在绝大多数的网站都已经使用了 HTTPS,要建立 HTTPS 链接,服务器和客户端之间首先要进行
TLS 握手,在握手过程中交换双方支持的 TLS 版本,加密算法等信息。不同的客户端之间的差异
很大,而且一般这些信息还都是稳定的,所以服务端就可以根据 TLS 的握手信息来作为特征,识别
一个请求是普通的用户浏览器访问,还是来自 Python 脚本等的自动化访问。
JA3 是生成 TLS 指纹的一个常用算法。它的工作原理也很简单,大概就是把以上特征拼接并求 md5。
查看 tls 指纹的网站有:
- https://tls.browserleaks.com/json
- TrackMe | Home
- https://kawayiyi.com/tls
不同网站的生成的指纹可能有差异,但是多次访问同一个网站生成的指纹是稳定的,而且能区分开
不同客户端。下文以第一个网站为例。
2.直接安装
pip install curl_cffi
功能简介:
- 支持JA3/TLS和http2指纹模拟;
- 比requests/tls_client快分开,和aiohttp/pycurl的速度比肩;
- 预编译,不需要自己的机器上再弄一遍;
- 支持asyncio,并且每个请求都可以换代理;
- 修改请求的API,支持http 2.0;
- 模仿requests。
先来看一段代码:
import requests
from pprint import pprint
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','dnt': '1','pragma': 'no-cache','sec-ch-ua': '"Chromium";v="118", "Microsoft Edge";v="118", "Not=A?Brand";v="99"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"macOS"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-origin','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46',
}response = requests.get('https://tls.browserleaks.com/json', headers=headers)
pprint(response.json())
运行效果:
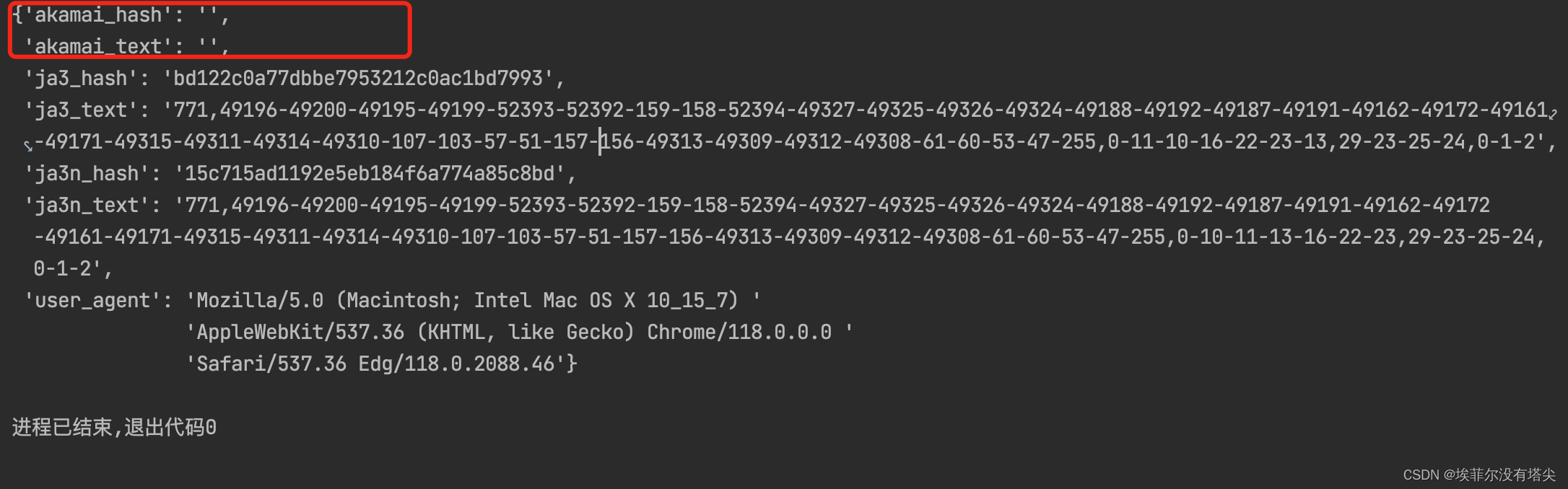
这是直接使用Requests发起的请求。你可以试一试,加上代理以后,这里的ja3_hash并不会发生变化。并且akamai_hash和akamai_text都是空。这个特征是非常明显的,网站直接根据这些特征就可以屏蔽你的爬虫。
于是为了完美模拟浏览器,国外大佬开发出了 curl-impersonate,将 curl 底层依赖的库全部换成了浏览器使用的库,并且版本也是一致的,这样生成的指纹就和浏览器完全一样了。
而 curl_cffi 正是 curl-impersonate 的 Python binding,我们直接使用 pip 安装即可。
那这个问题咋解决尼?
只需要 把 import requests 改成 from curl_cffi import requests。最后,在requests.get中加一个参数:impersonate="chrome110"
代码如下:
# import requests
from curl_cffi import requests
from pprint import pprint
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','dnt': '1','pragma': 'no-cache','sec-ch-ua': '"Chromium";v="118", "Microsoft Edge";v="118", "Not=A?Brand";v="99"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"macOS"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-origin','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46',
}response = requests.get('https://tls.browserleaks.com/json', headers=headers, impersonate="chrome110")
pprint(response.json())
这次再运行下代码:
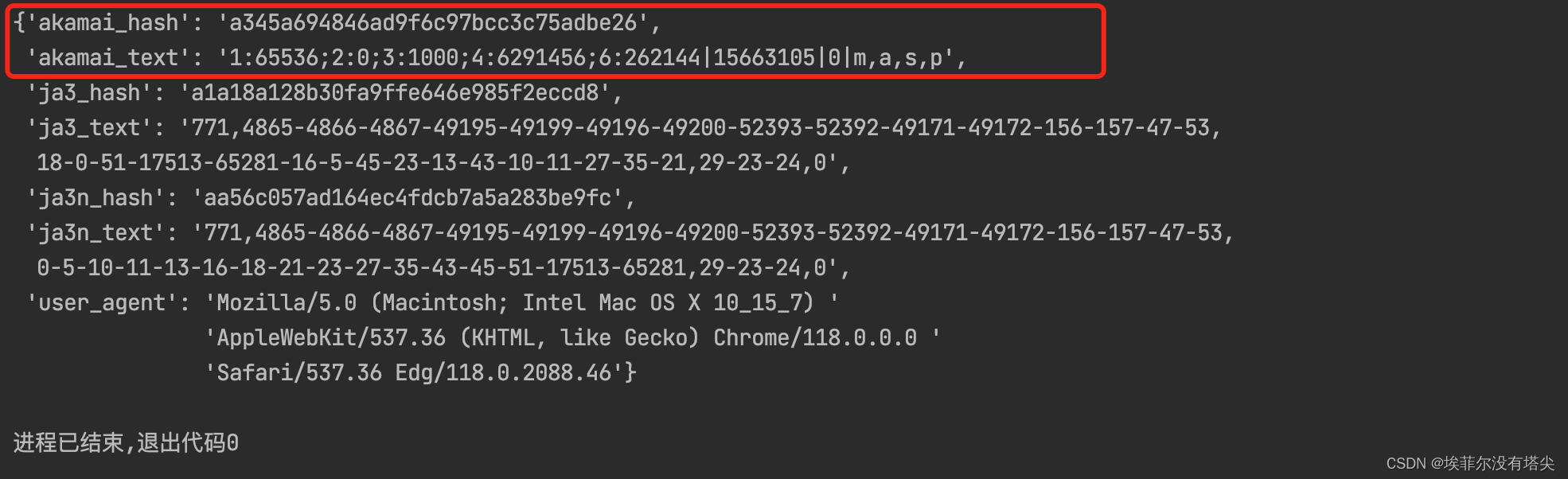
这次可以看到akamai_hash 和 akamai_text 已经都有了,网站已经无法识别你的爬虫了。在网站看来,这只是一个Chrome 110版本发起的请求。甚至Akamai需要的签名也都有了。
支持使用 Sessions
session = requests.Session()
也支持使用代理
proxies = {"https": "xxxxx:7890"}
proxies=proxies
支持模拟的浏览器版本:
- chrome99、
- chrome100、
- chrome101、
- chrome104、
- chrome107、
- chrome110、
- chrome99_android、
- edge99、
- edge101、
- safari15_3、
- safari15_5
同样它也支持asyncio,示例代码如下所示:
from curl_cffi.requests import AsyncSessionasync with AsyncSession() as s:r = await s.get("https://example.com")
要使用异步写法时,代码如下:
import asyncio
from curl_cffi.requests import AsyncSessionurls = ["https://googel.com/","https://facebook.com/","https://twitter.com/",
]async def main():async with AsyncSession() as s:tasks = []for url in urls:task = s.get("https://example.com")tasks.append(task)results = await asyncio.gather(*tasks)asyncio.run(main())
我们以这个网站为例: https://apk.support/ 分析下:
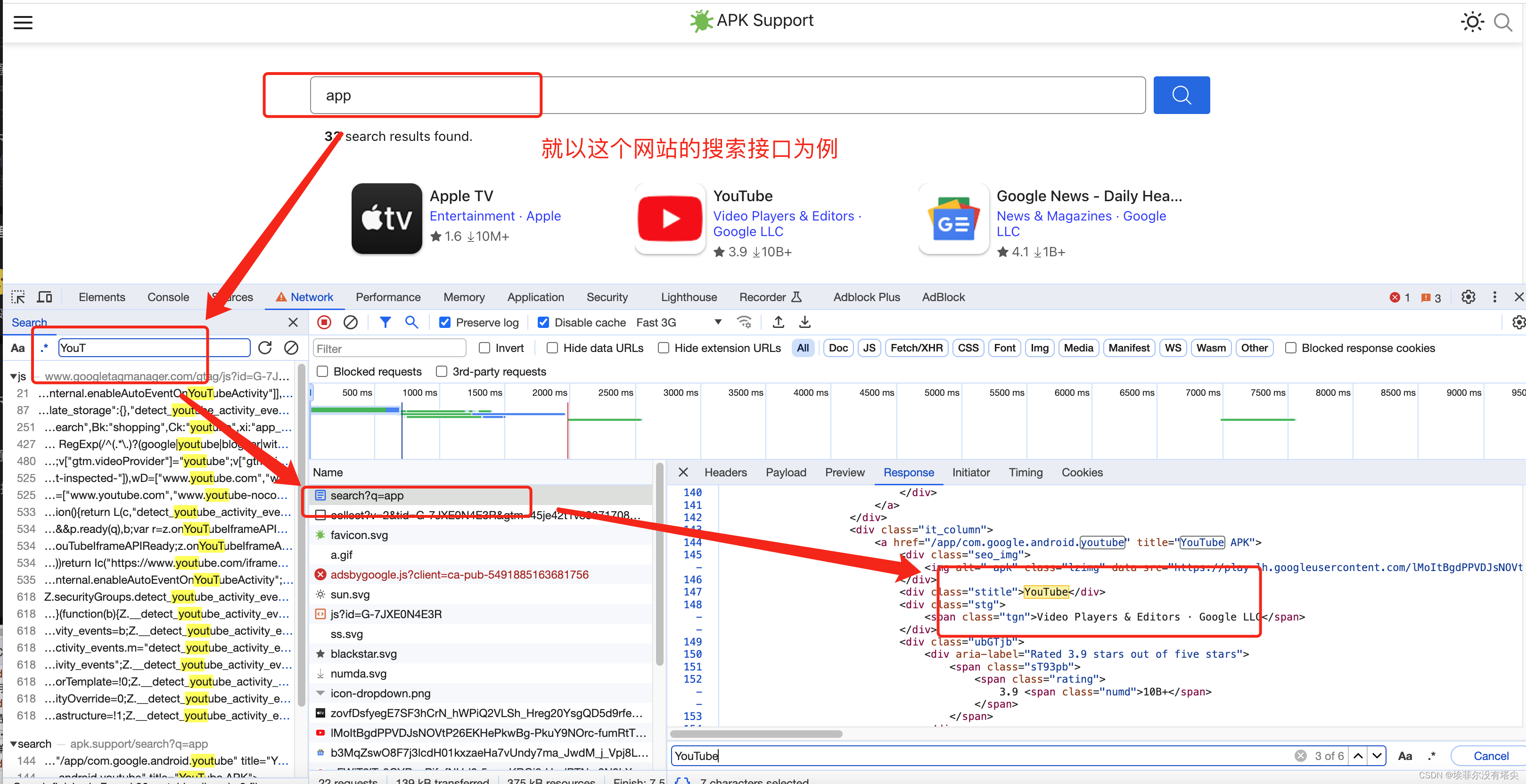
浏览器抓包是能看到页面返回的关键数据,但是再把这个请求放到postman 发个请求试一下:
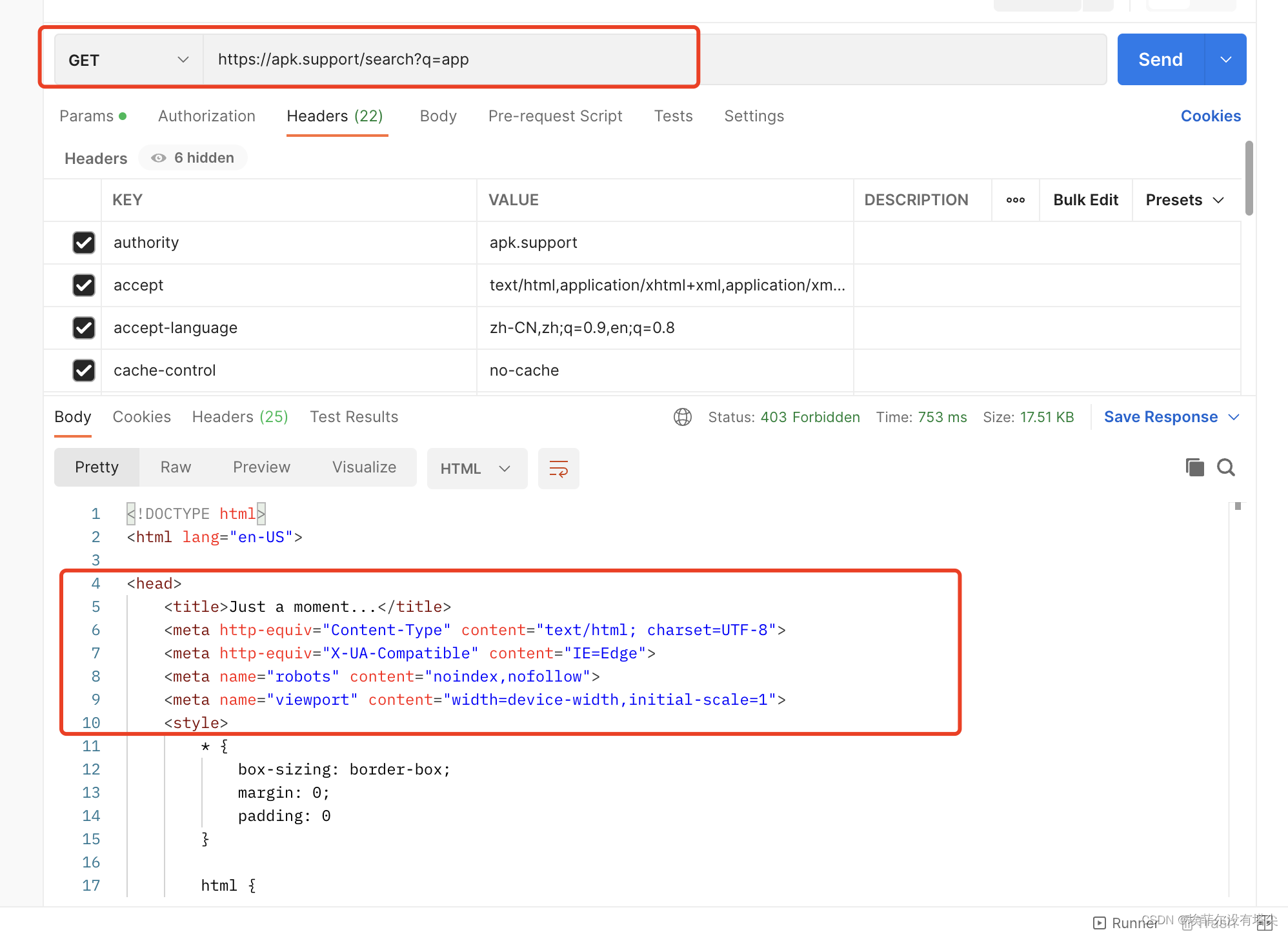
Just a moment...,完蛋凉了 标志性的5s盾。
咋办 用curl_cffi 发个请求试一试?
代码如下:
# import requests
from curl_cffi import requests
url = "https://apk.support/search?q=app"payload={}
headers = {'authority': 'apk.support','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8','cache-control': 'no-cache','pragma': 'no-cache','referer': 'https://apk.support/search?q=app','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"macOS"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-origin','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890','https': 'http://127.0.0.1:7890'
}
response = requests.get(url=url, headers=headers, impersonate="chrome110", proxies=proxies)print(response.text)
看看效果:
可以看到返回的已经是正常数据,不再是5s盾了。
参考链接:
https://mp.weixin.qq.com/s/Ch7taYpD-dnNL2FLOuxgGA
https://blog.csdn.net/qiulin_wu/article/details/134180011
https://blog.csdn.net/resphina/article/details/132507212
https://www.jb51.net/python/302044jai.htm