学seo可以做网站吗品牌设计

算法基本流程如下:
1. 采集音乐库
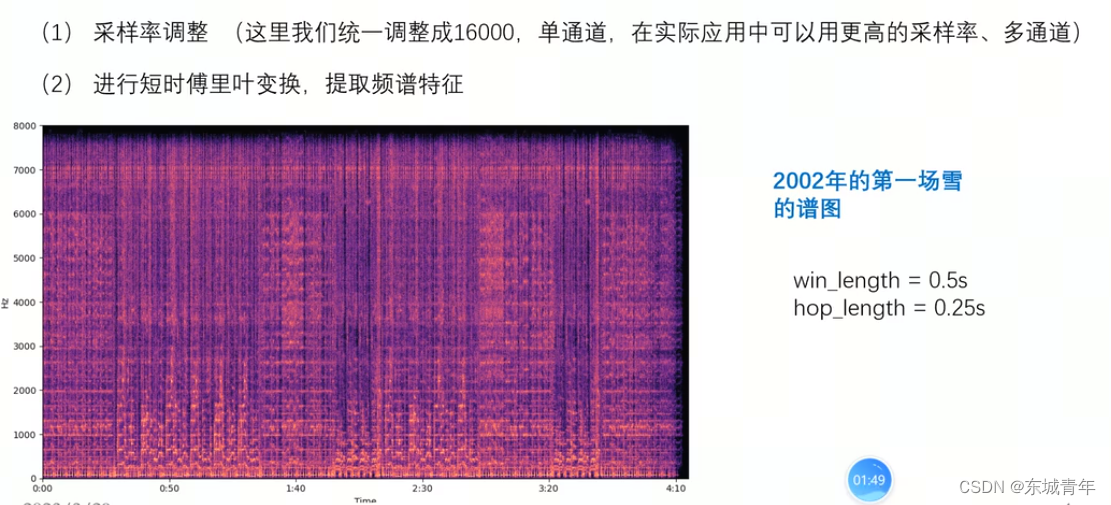
2. 音乐指纹采集
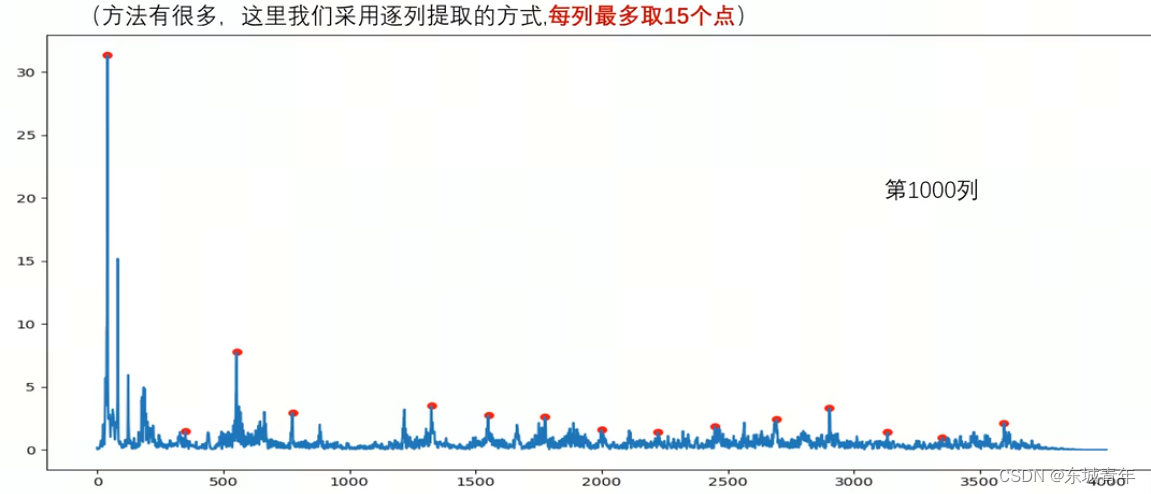
3. 采用局部最大值作为特征点
4. 将临近的特征点进行组合形成特征点对
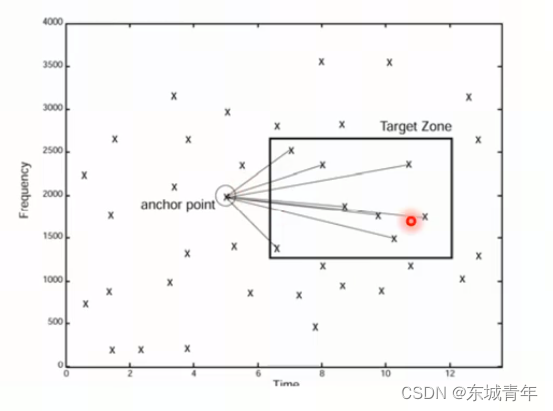
5. 对每个特征点对进行hash编码
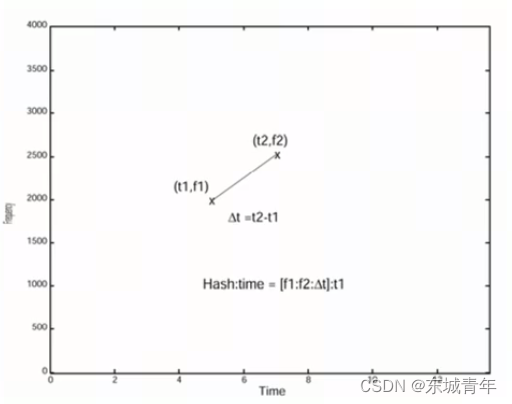
编码过程:将f1和f2进行10bit量化,其余bit用来存储时间偏移合集形成32bit的hash码
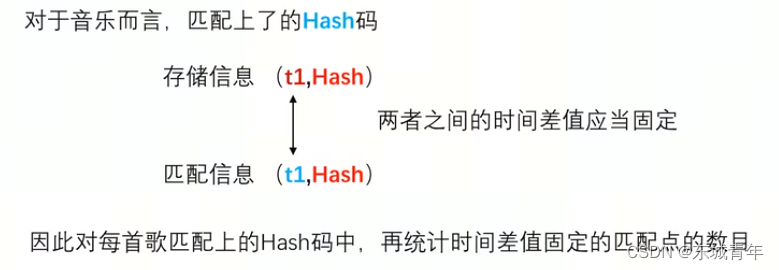
Hash = f1|f2<<10|diff_t<<20,存储信息(t1,Hash)
实现:
import numpy as np
import librosa
from scipy import signal
import pickle
import osfix_rate = 16000
win_length_seconds = 0.5
frequency_bits = 10
num_peaks = 15# 构造歌曲名与歌曲id之间的映射字典
def song_collect(base_path):index = 0dic_idx2song = {}for roots, dirs, files in os.walk(base_path):for file in files:if file.endswith(('.mp3', '.wav')):file_song = os.path.join(roots, file)dic_idx2song[index] = file_songindex += 1return dic_idx2song# 提取局部最大特征点
def collect_map(y, fs, win_length_seconds=0.5, num_peaks=15):win_length = int(win_length_seconds * fs)hop_length = int(win_length // 2)S = librosa.stft(y, n_fft=win_length, win_length=win_length, hop_length=hop_length)S = np.abs(S) # 获取频谱图D, T = np.shape(S)constellation_map = [] for i in range(T):spectrum = S[:, i]peaks_index, props = signal.find_peaks(spectrum, prominence=0, distance=200)# 根据显著性进行排序n_peaks= min(num_peaks, len(peaks_index))largest_peaks_index = np.argpartition(props['prominences'], -n_peaks)[-n_peaks:]for peak_index in peaks_index[largest_peaks_index]:frequency = fs / win_length * peak_index# 保存局部最大值点的时-频信息constellation_map.append([i, frequency])return constellation_map# 进行Hash编码
def create_hash(constellation_map, fs, frequency_bits=10, song_id=None):upper_frequency = fs / 2hashes = {}for idx, (time, freq) in enumerate(constellation_map):for other_time, other_freq in constellation_map[idx: idx + 100]: # 从邻近的100个点中找点对diff = int(other_time - time)if diff <= 1 or diff > 10: # 在一定时间范围内找点对continuefreq_binned = int(freq / upper_frequency * (2 ** frequency_bits))other_freq_binned = int(other_freq / upper_frequency * (2 ** frequency_bits))hash = int(freq_binned) | (int(other_freq) << 10) | (int(diff) << 20)hashes[hash] = (time, song_id)return hashes特征提取:feature_collect.py
# 获取数据库中所有音乐
path_music = 'data'
current_path = os.getcwd()
path_songs = os.path.join(current_path, path_music)
dic_idx2song = song_collect(path_songs)# 对每条音乐进行特征提取
database = {}
for song_id in dic_idx2song.keys():file = dic_idx2song[song_id]print("collect info of file", file)# 读取音乐y, fs = librosa.load(file, sr=fix_rate)# 提取特征对constellation_map = collect_map(y, fs, win_length_seconds=win_length_seconds, num_peaks=num_peaks)# 获取hash值hashes = create_hash(constellation_map, fs, frequency_bits=frequency_bits, song_id=song_id)# 把hash信息填充入数据库for hash, time_index_pair in hashes.items():if hash not in database:database[hash] = []database[hash].append(time_index_pair)# 对数据进行保存
with open('database.pickle', 'wb') as db:pickle.dump(database, db, pickle.HIGHEST_PROTOCOL)
with open('song_index.pickle', 'wb') as songs:pickle.dump(dic_idx2song, songs, pickle.HIGHEST_PROTOCOL)# 加载数据库
database = pickle.load(open('database.pickle', 'rb'))
dic_idx2song = pickle.load(open('song_index.pickle', 'rb'))
print(len(database))# 检索过程
def getscores(y, fs, database):# 对检索语音提取hashconstellation_map = collect_map(y, fs)hashes = create_hash(constellation_map, fs, frequency_bits=10, song_id=None)# 获取与数据库中每首歌的hash匹配matches_per_song = {}for hash, (sample_time, _) in hashes.items():if hash in database:maching_occurences = database[hash]for source_time, song_index in maching_occurences:if song_index not in matches_per_song:matches_per_song[song_index] = []matches_per_song[song_index].append((hash, sample_time, source_time))scores = {}# 对于匹配的hash,计算测试样本时间和数据库中样本时间的偏差for song_index, matches in matches_per_song.items():
# scores[song_index] = len(matches)song_scores_by_offset = {}# 对相同的时间偏差进行累计for hash, sample_time, source_time in matches:delta = source_time - sample_timeif delta not in song_scores_by_offset:song_scores_by_offset[delta] = 0song_scores_by_offset[delta] += 1# 计算每条歌曲的最大累计偏差max = (0, 0)for offset, score in song_scores_by_offset.items():if score > max[1]:max = (offset, score)scores[song_index] = maxscores = sorted(scores.items(), key=lambda x:x[1][1], reverse=True)return scores音乐检索:music_research.py
import threading
from playsound import playsounddef cycle(path):while 1:playsound(path)
def play(path, cyc=False):if cyc:cycle(path)else:playsound(path)path = 'test_music/record4.wav'
y, fs = librosa.load(path, sr=fix_rate)
# 播放待检索音频
music = threading.Thread(target=play, args=(path,))
music.start()# 检索打分
scores = getscores(y, fs, database)# 打印检索信息
for k, v in scores:file = dic_idx2song[k]name = os.path.split(file)[-1]# print("%s :%d"%(name, v))print("%s: %d: %d"%(name, v[0], v[1]))# 打印结果
if len(scores) > 0 and scores[0][1][1] > 50:print("检索结果为:", os.path.split(dic_idx2song[scores[0][0]])[-1])
else:print("没有搜索到该音乐")麦克风录音识别音乐:
import pyaudio
import waveRATE = 48000 # 采样率
CHUNK = 1024 # 帧大小
record_seconds = 10 # 录音时长s
CHANNWLS = 2 # 通道数# 创建pyaudio流
audio = pyaudio.PyAudio()stream = audio.open(format=pyaudio.paInt16, # 使用量化位数16位channels=CHANNWLS, # 输入声道数目rate=RATE, # 采样率input=True, # 打开输入流frames_per_buffer=CHUNK) # 缓冲区大小frames = [] # 存放录制的数据
# 开始录音
print('录音中。。。')
for i in range(0, int(RATE / CHUNK * record_seconds)):# 从麦克风读取数据流data = stream.read(CHUNK)# 将数据追加到列表中frames.append(data)# 停止录音,关闭输入流
stream.stop_stream()
stream.close()
audio.terminate()# 将录音数据写入wav文件中
with wave.open('test_music/test.wav', 'wb') as wf:wf.setnchannels(CHANNWLS)wf.setsampwidth(audio.get_sample_size(pyaudio.paInt16))wf.setframerate(RATE)wf.writeframes(b''.join(frames))# 打开录音文件
path = 'test_music/test.wav'
y, fs = librosa.load(path, sr=fix_rate)# 线程播放待检索音频
# music = threading.Thread(target=play, args=(path,))
# music.start()# 音乐检索
print('检索中。。。')
scores = getscores(y, fix_rate, database)# 打印检索信息
# for k, v in scores:
# file = dic_idx2song[k]
# name = os.path.split(file)[-1]
# # print("%s :%d"%(name, v))
# print("%s: %d: %d"%(name, v[0], v[1]))# 打印结果
if len(scores) > 0 and scores[0][1][1] > 50:print("检索结果为:", os.path.split(dic_idx2song[scores[0][0]])[-1])
else:print("没有搜索到该音乐")
参考:音乐检索-Shazam算法原理_哔哩哔哩_bilibili