专业免费建站如何进行网站性能优化
目录
项目背景
项目效果
SQLite的下载安装
使用JDBC操作SQLite
第三方库pinyin4j
pinyin4j的具体使用
封装pinyin4j
数据库的设计
创建实体类
实现DBUtil
封装FileDao
设计scan方法
多线程扫描
周期性扫描
控制台版本的客户端
图形化界面
设计图形化界面
项目背景
有的同学,电脑上的文件比较多,通过windows自带的文件搜索工具来进行查找,搜索起来非常慢,有很长的时间都在遍历磁盘.此时就可以使用更加高效的文件搜索工具,去进行文件查找.
业界内有一款非常知名的文件搜索工具-Everything.

当输入java之后,搜索的结果,可能是文件名就叫做java,也可能是文件名中包含了java.
我们要做的项目,就是仿everything的文件搜索工具.
项目效果
首先,我们要实现的是一个"图形化界面"程序.图形化界面程序的开发,java并非是主流的技术手段,绝大多数的图形化界面,都是使用C++/C#/前端的技术栈实现的.
但是,使用java也可以进行图形化界面的开发.
首先,我们先创建一个Maven项目.
想要实现一个快速的结果,就要提前把文件/目录结构扫描好,然后把扫描结果存储在数据库里,方便进行随时查询.
关于数据库的选择,对于我们之前使用的MySQL,在这个项目里不太适合.因为,MySQL数据库本身就好几百M,安装过程很麻烦,对于当前的轻量程序来说不适合.
更加适合的数据库-SQLite.
SQLite是一个轻量的关系型数据库,以数据表的形式来组织数据.整个SQLite数据库,只有1M左右大小的可执行程序.SQLite也是Android系统的内置数据库.
SQLite和MySQL在使用上非常相似,核心就在于SQL语句上,绝大部分的SQL语句是相同的.
SQLite的下载安装
找到SQLite的官方网站



下载可执行程序.
和MySQl不同的是,SQLite不是客户端服务器结构的程序.SQLite只是单独的可执行程序,对应的"数据库"直接以文件的方式来进行表示.
下载完成之后,直接双击exe,此时打开的SQLite客户端,直接使用了内存作为数据库的数据存储介质,这是不符合我们的要求的,我们是希望数据库能够进行持久化存储的.
所以我们要在此处shitf+右键文件资源管理器的空白区域,打开powershell或者cmd窗口,通过命令来创建一个保存到文件中的数据库.

SQLite里面没有针对库的操作,因为打开哪个文件,就相当于针对哪个数据库操作,删除对应文件,就是删除对应的数据库.

查看表,直接用.tables

SQLite提供的特殊命令,都是以.开头,并且不带分号,这些特殊命令可以通过.help来查看.
剩下的增删改查就都是一样的了.
使用代码操作SQLite和使用代码操作MySQl的差别不大.因为JDBC存在的意义就是为了屏蔽不同的数据库使用的差别.
使用JDBC操作SQLite
使用JDBC操作SQLite来操作,需要先加载一个驱动包,通过驱动包来简历JDBC api和SQLite原生api之间的联系.

粘贴到配置文件中

使用jdbc对sqlite数据库进行插入和查询
import org.sqlite.SQLiteDataSource;import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;public class TestSQLite {public static void main(String[] args) throws SQLException {testInsert();testSelect();}private static void testInsert() throws SQLException {//往sqlite中插入数据//1.创建数据源//指定数据库文件所在路径DataSource dataSource = new SQLiteDataSource();((SQLiteDataSource)dataSource).setUrl("jdbc:sqlite://D:\\downloadSoftware\\sqlite\\sqlite-tools-win32-x86-3420000/test3.db");//2.建立连接Connection connection = dataSource.getConnection();//3.构造sql语句String sql = "insert into test values(?,?)";PreparedStatement statement = connection.prepareStatement(sql);statement.setInt(1,11);statement.setString(2,"李四");//4.执行sql语句statement.executeUpdate();//5.释放资源statement.close();connection.close();}private static void testSelect() throws SQLException {//从sqlite中进行查询//1.创建数据源DataSource dataSource = new SQLiteDataSource();((SQLiteDataSource)dataSource).setUrl("jdbc:sqlite://D:\\downloadSoftware\\sqlite\\sqlite-tools-win32-x86-3420000/test3.db");//2.建立连接Connection connection = dataSource.getConnection();//3.构造sql语句String sql = "select * from test";PreparedStatement statement = connection.prepareStatement(sql);//4.执行sqlResultSet resultSet = statement.executeQuery();//5.遍历结果集合while (resultSet.next()){int id = resultSet.getInt("id");String name = resultSet.getString("name");System.out.println("id: " + id + " name: " + name);}//6.释放资源resultSet.close();statement.close();connection.close();}
}
第三方库pinyin4j
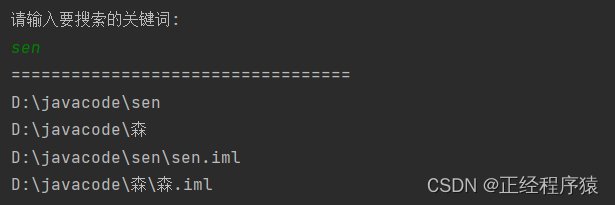
我们的程序中,能够支持按照拼音来搜索.比如当前的有些文件或者目录名字是中文的,我们输入中文的汉语拼音能够搜索到对应的文件.
假设有一个文件夹叫做基础语法,此时我们输入jcyf,能够搜索到.
为了实现按照拼音来操作,就需要把汉字字符串转换成拼音.这个功能,标准库里没有.但是有一些第三方库,可以实现根据汉字获取拼音.
我们使用pinyin4j来实现上述的功能.通过maven中央仓库,下载pinyin4j.

<!-- https://mvnrepository.com/artifact/com.belerweb/pinyin4j -->
<dependency><groupId>com.belerweb</groupId><artifactId>pinyin4j</artifactId><version>2.5.1</version>
</dependency>
pinyin4j的具体使用
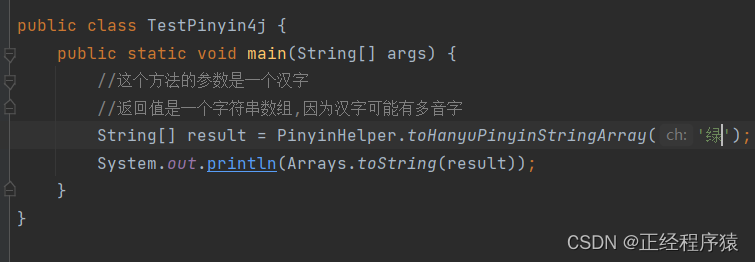

通过数字表示音调.u:表示yu这个音.但是我们更多的是用yv来表示.
封装pinyin4j
针对上述api进行简单的封装,实现针对汉字字符串获取到拼音.
package util;import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat;
import net.sourceforge.pinyin4j.format.HanyuPinyinVCharType;
import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination;public class PinyinUtil {/*** @param src : 汉语拼音字符串* @param fullSpell : 是否得到全拼* true:得到全拼* false:得到拼音首字母* 此处针对多音字不做过多考虑!!!只取它的第一个发音作为结果!!!* @return*/public static String get(String src,boolean fullSpell){//trim效果就是去掉字符串两侧的空白字符if(src == null || src.trim().length() == 0){//空的字符串return null;}//针对u:转换为vHanyuPinyinOutputFormat format = new HanyuPinyinOutputFormat();format.setVCharType(HanyuPinyinVCharType.WITH_V);//遍历每个字符,针对每个字符分别进行转换//把拼音结果拼接到StringBuilder中StringBuilder stringBuilder = new StringBuilder();for (int i = 0; i < src.length(); i++){char ch = src.charAt(i);//针对单个字符进行转换String[] tmp = null;try {//将配置作为参数传递tmp = PinyinHelper.toHanyuPinyinStringArray(ch,format);} catch (BadHanyuPinyinOutputFormatCombination e) {e.printStackTrace();}if (tmp == null || tmp.length == 0){//如果结果是空的数组,说明转换失败//输入的字符没有汉语拼音就转换失败//不能转换就保留原始字符stringBuilder.append(ch);}else if (fullSpell == true){//获取全拼stringBuilder.append(tmp[0]);}else {//获取首字母stringBuilder.append(tmp[0].charAt(0));}}return stringBuilder.toString();}
}
数据库的设计
先确认实体,在确认实体之间的关系.
我们使用数据库来保存文件/目录信息.
此处设计的实体只有文件.(此处针对文件或者目录的查找没有区别).
表名file_meta:存的是文件的属性数据,而不是文件内容.meta就代表属性信息或者是元数据.
create table if not exists file_meta(id INTEGER primary key autoincrement,name varchar(50) not null,path varchar(512) not null,is_directory boolean not null,pinyin varchar(100) not null,pinyin_first varchar(50) not null,size BIGINT not null,last_modified timestamp not null
);在这里,id的类型必须是写作INTEGER而不能写作int.
因为在SQLite数据库中,对于自增主键的修饰,必须为INTEGER.
接下来准备通过程序,通过jdbc来自动执行这个建表语句.而不是直接复制粘贴到客户端中.
因为当下写的程序不是服务器端程序,而是一个客户端程序,是给普通用户使用的.
因为写了if not exists,所以存在了就不会在创建,所以反复执行没有副作用.
因此就可以让程序每次启动的时候都运行一下这个sql.确保是把表建好了,在执行后续的操作.
创建实体类
创建一个类,用这个类的实例来表示表中的每一条记录.
package dao;import javafx.scene.input.DataFormat;
import util.PinyinUtil;import java.io.File;
import java.math.BigDecimal;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Objects;//这个类的实例就代表file_meta表中的每个记录
public class FileMeta {private int id;private String name;private String path;private boolean isDirectory;//下面两个属性,在java代码中可以没有//都是根据上述的name属性来的//可以直接实现两个get方法来获取// private String pinyin;//private String pinyinFirst;//size单位是字节,我们最终给界面显示的不应该以字节为单位private long size;//last_modified是时间戳,这也是一个很大的数字//所以也要进行格式化转换private long lastModified;public String getPinyin(){return PinyinUtil.get(name,true);}public String getPinyinFirst(){return PinyinUtil.get(name,false);}public String getSizeText(){//通过这个方法,把size的值进行合理的单位换算,变成更加易读的值// 单位主要是:Byte,KB,MB,GB//由于单个文件不太可能达到TB,所以只考虑这四个单位//看size的大小进行单位的换算//size<1024直接使用Byte//size>=1024 并且 < 1024*1024 ,单位使用kb,以此类推double curSize = size;String[] units = {"Byte","KB","MB","GB"};for (int level = 0; level < units.length; level++) {if (curSize < 1024){//new BigDecimal()更加精确的表示小数return String.format("%.2f " +units[level],new BigDecimal(curSize));}curSize/=1024;}//当单位升级到GB还不够用,就直接使用GBreturn String.format("%.2f GB",new BigDecimal(curSize));}public String getLastModifiedText(){///通过这个方法来进行时间戳到时间格式化的转换DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");return dateFormat.format(lastModified);}public FileMeta(String name, String path, boolean isDirectory, long size, long lastModified) {this.name = name;this.path = path;this.isDirectory = isDirectory;this.size = size;this.lastModified = lastModified;}public FileMeta(File f){this(f.getName(), f.getParent(), f.isDirectory(), f.length(), f.lastModified());}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getPath() {return path;}public void setPath(String path) {this.path = path;}public boolean isDirectory() {return isDirectory;}public void setDirectory(boolean directory) {isDirectory = directory;}public long getSize() {return size;}public void setSize(long size) {this.size = size;}public long getLastModified() {return lastModified;}public void setLastModified(long lastModified) {this.lastModified = lastModified;}@Overridepublic boolean equals(Object o){if (this == o){//看看是不是和自己比较return true;}if (o == null){//针对o为null的特殊处理return false;}if (o.getClass() != this.getClass()){//比较类型return false;}FileMeta fileMeta =(FileMeta) o;return name.equals(fileMeta.name)&& path.equals(fileMeta.path)&& isDirectory == fileMeta.isDirectory;}//当前已经重写equals了,根据Java的相关编程规范,我们也要重写hashCode@Overridepublic int hashCode() {return Objects.hash(name, path, isDirectory);}
}
实现DBUtil
将使用jdbc获取数据源,建立连接,释放资源封装称为方法.
package dao;import org.sqlite.SQLiteDataSource;import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;public class DBUtil {//使用单例模式来提供DataSource//volatileprivate static volatile DataSource dataSource = null;public static DataSource getDataSource(){if (dataSource == null) {synchronized (DBUtil.class) {if (dataSource == null) {dataSource = new SQLiteDataSource();((SQLiteDataSource) dataSource).setUrl("jdbc:sqlite://D:\\downloadSoftware\\sqlite\\sqlite-tools-win32-x86-3420000/fileSearch.db");}}}return dataSource;}public static Connection getConnection() throws SQLException {return getDataSource().getConnection();}public static void close(Connection connection, PreparedStatement statement, ResultSet resultSet){//分成3个部分try-catch://为了防止有一个close出异常了,其他的close执行不到.if (resultSet != null){try {resultSet.close();} catch (SQLException e) {e.printStackTrace();}}if (statement!=null){try {statement.close();} catch (SQLException e) {e.printStackTrace();}}if (connection!=null){try {connection.close();} catch (SQLException e) {e.printStackTrace();}}}
}
封装FileDao
针对file_meta表进行增删改查操作的封装.
package dao;import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;//通过这个类封装针对file_meta表的操作
public class FileDao {//1.初始化数据库(建表)//程序实现对表的创建(客户端程序)public void initDB(){//1.读取到db.sql中的SQL语句//2.根据SQL语句调用jdbc执行操作Connection connection = null;Statement statement = null;try {connection = DBUtil.getConnection();//此处必须要使用Statement而不是PreparedStatement//因为接下来的操作是建表操作不是增删改查statement = connection.createStatement();String[] sqls = getInitSQL();for (String sql: sqls) {System.out.println("[initDB] sql " + sql);statement.executeUpdate(sql);}} catch (SQLException e) {e.printStackTrace();}finally {DBUtil.close(connection,statement,null);}}//从db.sql中读取文件内容//db.sql中可能有多个sql语句//所用用字符串数组接收,每个元素都是独立的sql语句private String[] getInitSQL(){//存储最终结果StringBuilder stringBuilder = new StringBuilder();//此处需要动态获取到db.sql文件的路径,而不是一个写死的路径//当前db.sql所在的resources目录,是一个特殊的目录//这个目录在java项目中,作为一个"Resources Root"//资源文件根目录//资源文件就包括不限于程序运行依赖的图片,音频,视频,图标,字体等等//所以Java中也提供了特定的方法,能够获取到resources对应的目录//先获取到当前类的类对象,在获取到当前类对象的类加载器//在通过getResourceAsStream()方法获取到resources目录下的文件//针对二进制文件我们使用字节流//针对文本文件使用字符流try(InputStream inputStream = FileDao.class.getClassLoader().getResourceAsStream("db.sql")){//字节流转换为字符流try(InputStreamReader inputStreamReader = new InputStreamReader(inputStream,"utf8")){while (true){//int 接收,-1表示结束int ch = inputStreamReader.read();if (ch == -1){//文件读取完毕break;}stringBuilder.append((char)ch);}}}catch (IOException e){e.printStackTrace();}//用分号作为分隔符//作为每个sql语句的分割//保证每个元素作为一个sql语句return stringBuilder.toString().split(";");}//2.插入文件/目录数据到数据库中//这里是提供一个批量插入的方法//针对add方法,需求是能够针对一组文件数据进行插入操作.//可以针对每个FileMeta分别进行插入,在套个循环//但是更好的做法是采用事务//事务本身就是用来批量执行一组sql的//而且使用事务批量执行任务,要比上述每次执行一个分多次执行更加高效//效果类似于"锁粗化"(反复针对同一个锁多次加锁解锁不如合并成大的加锁解锁操作)//使用jdbc操作事务://1.先把连接的自动提交功能关闭,默认情况下jdbc中的connection每次执行了一个execute方法//都会产生一次和数据库的交互,为了同一在最开始的时候进行加锁,统一在最后进行解锁,就需要关闭自动提交功能//jdbc默认情况下,每次执行一个sql,都是一个事务,只不过此时的事务里只有一个sql//2.针对每个要执行的sql,使用PreparedStatement提供的addBatch方法进行累计//我们之前认为的是PreparedStatement里面只包含了一个sql//但是实际上,PreparedStatement里面是可以包含多个sql的//这里包含的每个sql成为是一个batch//3.添加好了所有要执行的batch之后,统一进行executeBatch,执行上述所有的sql//4.使用commit,告诉数据库执行完毕了.同时commit也会把这个连接针对数据库上的锁进行释放了//5.如果上述执行过程中出现异常,此时可以使用rollback进行回滚.public void add(List<FileMeta> fileMetas){Connection connection = null;PreparedStatement preparedStatement = null;try {connection = DBUtil.getConnection();//关闭连接的自动提交功能connection.setAutoCommit(false);String sql = "inset into file_meta values(null,?,?,?,?,?,?,?)";preparedStatement = connection.prepareStatement(sql);for (FileMeta fileMeta: fileMetas) {//针对当前fileMeta对象替换到sql语句中preparedStatement.setString(1,fileMeta.getName());preparedStatement.setString(2,fileMeta.getPath());preparedStatement.setBoolean(3,fileMeta.isDirectory());preparedStatement.setString(4, fileMeta.getPinyin());preparedStatement.setString(5,fileMeta.getPinyinFirst());preparedStatement.setLong(6,fileMeta.getSize());preparedStatement.setTimestamp(7,new Timestamp(fileMeta.getLastModified()));//使用addBatch,把构造好的sql片段累计起来//addBatch会把构造好的sql保存好,同时又允许构造好一个新的sql出来preparedStatement.addBatch();}//执行所有的sql片段preparedStatement.executeBatch();//执行完毕,commit告知数据库connection.commit();} catch (SQLException e) {//出现异常,就进行回滚try {connection.rollback();} catch (SQLException ex) {ex.printStackTrace();}}finally {DBUtil.close(connection,preparedStatement,null);}}//3.按照特定的关键词进行查询//在文件搜索的时候必备的功能//此处的pattern可能是文件名的一部分也可能是文件名拼音的一部分,也可能是文件名拼音首字母的一部分public List<FileMeta> searchByPattern(String pattern){List<FileMeta> fileMetas = new ArrayList<>();Connection connection = null;PreparedStatement statement = null;ResultSet resultSet = null;try {connection = DBUtil.getConnection();String sql = "select name,path,is_directory,size,last_modified from file_meta"+" where name like ? or pinyin like ? or pinyin_first like ?"+" order by path,name";statement = connection.prepareStatement(sql);statement.setString(1,"%" + pattern + "%");statement.setString(2,"%" + pattern + "%");statement.setString(3,"%" + pattern + "%");resultSet = statement.executeQuery();while (resultSet.next()){String name = resultSet.getString("name");String path = resultSet.getString("path");Boolean isDirectory = resultSet.getBoolean("is_directory");long size = resultSet.getLong("size");Timestamp lastModified = resultSet.getTimestamp("last_modified");FileMeta fileMeta = new FileMeta(name,path,isDirectory,size,lastModified.getTime());fileMetas.add(fileMeta);}} catch (SQLException e) {e.printStackTrace();}finally {DBUtil.close(connection,statement,resultSet);}return fileMetas;}//4.给定路径,查询这个路径下的文件//在后续重新扫描,更新数据库的时候用到public List<FileMeta> searchByPath(String targetPath){List<FileMeta> fileMetas = new ArrayList<>();Connection connection = null;PreparedStatement statement = null;ResultSet resultSet = null;try {connection = DBUtil.getConnection();String sql = "select name,path,is_directory,size,last_modified from file_meta"+" where path = ?";statement = connection.prepareStatement(sql);statement.setString(1,targetPath);resultSet = statement.executeQuery();while (resultSet.next()){String name = resultSet.getString("name");String path = resultSet.getString("path");Boolean isDirectory = resultSet.getBoolean("is_directory");long size = resultSet.getLong("size");Timestamp lastModified = resultSet.getTimestamp("last_modified");FileMeta fileMeta = new FileMeta(name,path,isDirectory,size,lastModified.getTime());fileMetas.add(fileMeta);}} catch (SQLException e) {e.printStackTrace();}finally {DBUtil.close(connection,statement,resultSet);}return fileMetas;}//5.删除数据//文件从磁盘删掉了,此时就需要把数据库里的内容也删掉//删除的时候可能删除的是普通的文件,此时直接删除对应的表记录即可//删除的时候也可能是删除的目录,此时就需要把目录包含的子文件/子目录一并删除掉public void delete(List<FileMeta> fileMetas) {Connection connection = null;PreparedStatement statement = null;try {connection = DBUtil.getConnection();connection.setAutoCommit(false);//此处构造的sql要根据当前删除的内容情况,来区分对待for (FileMeta fileMeta:fileMetas) {String sql = null;if (!fileMeta.isDirectory()){//针对普通文件sql = "delete from file_meta where name=? and path=?";} else {//针对目录的删除操作//path like ? 要被替换成形如'd:/test%',删除子目录和子文件sql = "delete from file_meta where (name=? and path=?) or (path like ?)";}//此处不能像前面的add一样使用addBatch,addBatch前提是,sql是一个模板//把?替换成不同的值,此处的sql不一定使相同的//所以此处就需要重新构造出statement对象表示这个sql了.statement = connection.prepareStatement(sql);if (!fileMeta.isDirectory()){//普通文件,需要替换两个?statement.setString(1,fileMeta.getName());statement.setString(2,fileMeta.getPath());}else {//针对目录statement.setString(1,fileMeta.getName());statement.setString(2,fileMeta.getPath());statement.setString(3,fileMeta.getPath()+File.separator+fileMeta.getName()+File.separator+"%");}//真正执行删除操作statement.executeUpdate(sql);System.out.println("[delete]" + fileMeta.getPath() +'/'+ fileMeta.getName());//此处代码有多个statement对象,每一个对象都要关闭statement.close();}connection.commit();} catch (SQLException e) {try {connection.rollback();} catch (SQLException ex) {ex.printStackTrace();}}finally {DBUtil.close(connection,null,null);}}
}
设计scan方法
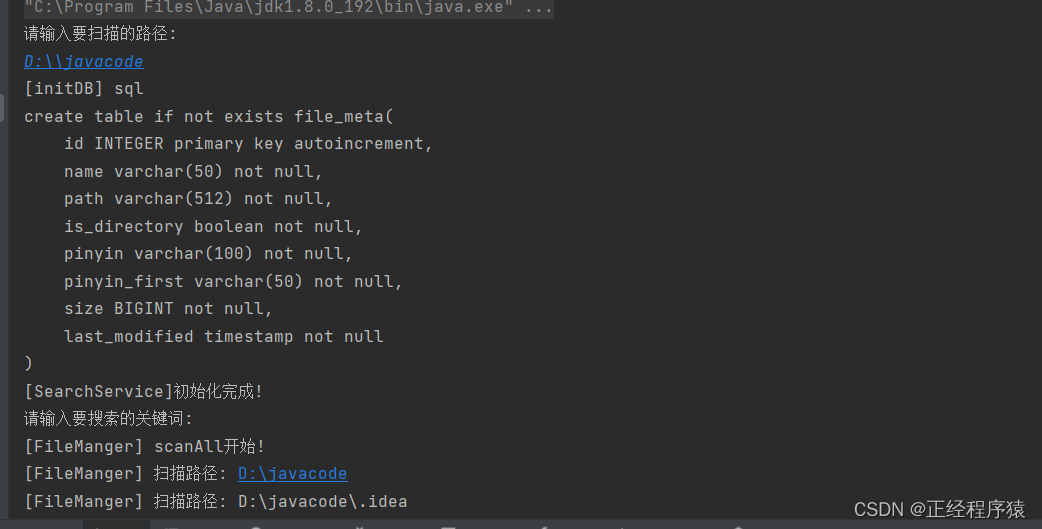
我们已经封装了对数据库表的操作,那么数据库表里的内容,从何而 来?
这就需要我们专门写代码,来遍历分析目录结构,把目录里面的文件/子目录都获取出来,并存入数据库中.
我们单独创建一个类,来完成对指定目录的扫描操作.
scan方法是对当前指定目录的扫描,仅仅只针对当前目录,不包含子目录/孙子目录.
scanAll则是针对指定目录的全方位扫描,包括子目录和孙子目录.
所以scan方法是作为扫描目录的一个基本操作.
scanAll方法里面递归调用scan方法就是对所有文件的全盘扫描.
package manger;import dao.FileDao;
import dao.FileMeta;
import javafx.scene.Parent;import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;//针对目录进行扫描
//并把扫描结果同步更新到数据库中
public class FileManger {private FileDao fileDao = new FileDao();//初始化设置选手数目为1,当线程池执行完所有任务之后,就立即调用一次countDown撞线private CountDownLatch countDownLatch = null;//用来衡量任务结束的计数器//AtomicInteger是线程安全的private AtomicInteger taskCount = new AtomicInteger(0);//通过这个方法,实现针对basePath描述的目录中内容的扫描//把这里的文件和子目录都扫描清楚,并且保存在数据库中public void scanAll(File basePath){System.out.println("[FileManger] scanAll开始!");long beg = System.currentTimeMillis();//countDownLatch为什么不直接在属性里面初始化??//保证每次调用scanAll都能初始化countDownLatch为1//防止周期性扫描多次扫描调用scanAll方法时//countDownLatch已经为0了//此时countDownLatch.await()就不起作用了//countDownLatch.await()方法只有countDownLatch不为0时才进行等待countDownLatch = new CountDownLatch(1);//scanAllByOneThread(basePath);scanAllByThreadPool(basePath);try {countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}long end =System.currentTimeMillis();System.out.println("[FileManger] scanAll结束! 执行时间: " + (end - beg) + "ms");}private static ExecutorService executorService = Executors.newFixedThreadPool(8);private void scanAllByThreadPool(File basePath){if (!basePath.isDirectory()) {return;}//计数器自增taskCount.getAndIncrement();//taskCount++;//扫描操作放到线程池里完成executorService.submit(new Runnable() {@Overridepublic void run() {try {scan(basePath);} finally {//放到finally里确保能够执行到//计数器自减taskCount.getAndDecrement();if (taskCount.get() == 0){//计数器为0就通知主线程停止计时countDownLatch.countDown();}}}});//继续递归其他目录File[] files = basePath.listFiles();if (files == null || files.length == 0 ){//当前目录下没东西return;}for (File f: files) {if (f.isDirectory()){scanAllByThreadPool(f);}}}//传入路径(目录),进行遍历private void scanAllByOneThread(File basePath){//现针对当前目录进行扫描scan(basePath);//列出当前目录下包含的所有文件File[] files = basePath.listFiles();if (files == null || files.length == 0 ){//当前目录下没东西return;}for (File f: files) {if (f.isDirectory()){scanAllByOneThread(f);}}}//scan方法针对一个目录进行处理(整个遍历目录过程中的基本操作)//这个方法只针对当前path对应的目录进行分析//列出这个path下包含的文件和子目录,并且把这些内容更新到数据库中//更新意味着这里的操作可能涉及到插入也可能涉及到删除//此方法不考虑子目录里的内容private void scan(File path){System.out.println("[FileManger] 扫描路径: " + path.getAbsolutePath());//1.列出文件系统上的真实的文件或者目录//scanned用来保存文件系统上有的List<FileMeta> scanned = new ArrayList<>();File[] files = path.listFiles();if (files != null){for (File file: files) {scanned.add(new FileMeta(file));}}//2.列出数据库当前指定目录里的内容List<FileMeta> saved = fileDao.searchByPath(path.getPath());//3.找出文件系统中没有的,数据库中有的,把这些内容删除掉List<FileMeta> forDelete = new ArrayList<>();//存储要删除的内容for (FileMeta fileMeta:saved) {//注意contains方法if (!scanned.contains(fileMeta)){forDelete.add(fileMeta);}}fileDao.delete(forDelete);//4.找出文件系统有的,数据库中没有的,往数据库中插入List<FileMeta> forAdd = new ArrayList<>();for (FileMeta fileMeta:scanned) {if (!saved.contains(fileMeta)){//找出文件系统中有的,数据库中没有的forAdd.add(fileMeta);}}fileDao.add(forAdd);}
}
在scan方法里面,涉及到对数据库的更新,更新可能涉及到插入也可能涉及到删除.
scanned用来保存文件系统上真实的文件/目录.
saved用来保存数据库上保存的指定目录里的内容.
对这scanned和saved中的元素进行比较,scanned中有的,saved中没有的,进行数据库插入;
scanned中没有的,saved中有的,进行数据库的删除.
注意:
我们在这个方法里进行比较的时候,使用的是集合中contains方法,此方法本质上是在进行"对象比较相等".剖析此方法,可以发现其底层在进行元素之间比较的时候,其实是调用的equals方法.而默认的equals方法,默认是比较两个对象的地址.如果是比较对象的地址,此处scanned和saved中包含的对象的地址一定是不同的,因为它们是在不同的地方new出来的对象.所以此处必须要显示指定比较的规则.
所以我们要在FileMeta实体类里面重写equals方法,显式指定比较的规则.
在此处,我们比较两个文件对象是否相等,主要看三个地方:文件名,文件所在路径和是否是目录.
所以我们在是实体类里根据这三个属性重写equals.
还需要注意的是,我们在此方法里都使用了实体类里的构造方法:
public FileMeta(File f){this(f.getName(), f.getParent(), f.isDirectory(), f.length(), f.lastModified());
}
这里的f.getParent()不能写作f.getPath().
实体类里的path对应的文件所在的目录,而File类中的getPath方法是获得包含当前文件的完整路径.
此处的f.getParent()获取只是当前所在的目录.
多线程扫描
为了提高扫描的效率,我们可以把上述类里的单线程扫描升级称为多线程扫描.
针对多线程扫描,我们可以手动创建几个线程.更好的做法,是使用线程池.
接下来的工作就是将当前的扫描工作拆分成多个小任务,来交给线程池里的线程完成.
此处在我们的程序里,恰好可以切分扫描工作.
每次扫描到一个目录,都需要调用scan方法,来针对当前目录进行分析和数据库的更新.
于是我们就可以将每个scan操作都作为一个小任务来提交给线程池.

创建一个线程池,加上staic,此线程池就变为单例了.
当我们升级为多线程扫描后,会有一个问题.
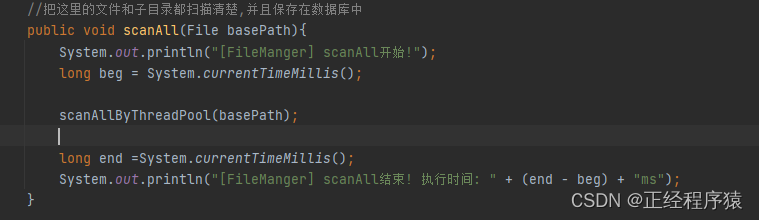
由于我们把扫描操作交给了线程池,此时主线程只负责目录的遍历操作.那么就有一种可能,遍历目录的功能极快就完成了,而扫描工作还需要很长时间完成.那么此时,上述方法里的计时,就不准确了.
这里的计时就只是遍历目录的时间,只记录了主线程的工作时间.计算的时间会有很大的误差.
为了解决这一问题,我们可以使用CountDownLatch.
CountDownLatch是一个同步工具类,它通过一个计数器来实现的,初始值为线程的数量。每当一个线程完成了自己的任务,计数器的值就相应得减1。当计数器到达0时,表示所有的线程都已执行完毕,然后在等待的线程就可以恢复执行任务。

由于此处我们使用的是线程池,先让主线程await(),可以提前遍历任务的数量,然后进行第二次遍历每当完成一个任务,就countDown()一次.
在这里,还有一个取巧的做法,不用提前遍历.
引入一个计数器,每次给线程池添加任务的时候,都让计数器+1,线程池每次完成一个任务,就让计数器-1.当计数器为0的时候,就视为所有的任务都执行完了.
注意
使用此方法有一个大的前提,就是添加任务的速度要远远大于执行任务的速度.在当前的代码里,由于扫描工作要涉及到数据库的更新所以执行任务的速度要远远大于添加任务的速度.
如果执行任务的速度和添加任务的速度差不多,那么就有可能出现,添加了一个任务之后,计数器+1,执行完了,计数器-1,此是第二个任务还没有添加上,那么这种情况程序认为已经没有任务了,就结束了.

周期性扫描
package service;import dao.FileDao;
import dao.FileMeta;
import manger.FileManger;import java.io.File;
import java.util.List;//通过此类来描述整个程序的核心业务逻辑
public class SearchService {private FileDao fileDao = new FileDao();private FileManger fileManger = new FileManger();//使用此线程周期性扫描文件系统private Thread t = null;//1.提供一个初始化操作public void init(String basePath){//初始情况下,就把数据库初始化好,并且进行一个初始的扫描操作fileDao.initDB();t = new Thread(()->{while (!t.isInterrupted()){//将耗时操作放到扫描线程里//不要放到主线程里//如果将此耗时操作放到主线程里//那么在扫描过程中,在图形化界面里操作会造成界面未响应的现象fileManger.scanAll(new File(basePath));try {Thread.sleep(60000);} catch (InterruptedException e) {e.printStackTrace();break;}}});t.start();System.out.println("[SearchService]初始化完成!");}//使用此方法让扫描线程停止下来public void shutDown(){//判断一下,防止出现空指针异常if (t != null) {t.interrupt();}}//2.提供一个查找方法public List<FileMeta> search(String pattern){return fileDao.searchByPattern(pattern);}}
我们实现的多线程扫描,只是发生在程序启动的时候,如果当前程序启动,扫描完成之后,用户针对文件系统的内容做出调整,我们是无法感知到的.
所以,我们需要额外创建一个线程,来执行周期性扫描目录的操作,以便及时的感知文件的变化,从而做出修改.
控制台版本的客户端
我们基本的工作都已经完成了,接下来就写一个main方法,来运行一下.
import dao.FileMeta;
import service.SearchService;import java.io.File;
import java.util.List;
import java.util.Scanner;public class ConsoleClient {public static void main(String[] args) {//先让用户输入一个扫描的文件路径//然后再让用户输入一个具体要查询的词//根据这个词展开搜索Scanner scanner = new Scanner(System.in);System.out.println("请输入要扫描的路径: ");String bathPath = scanner.next();//针对该路径进行初始化SearchService searchService =new SearchService();searchService.init(bathPath);//创建一个主循环,反复的读取数据,并进行搜索功能while (true){System.out.println("请输入要搜索的关键词: ");String word = scanner.next();List<FileMeta> fileMetaList = searchService.search(word);System.out.println("==================================");for (FileMeta fileMeta: fileMetaList) {System.out.println(fileMeta.getPath() + File.separator + fileMeta.getName());}System.out.println("==================================");}}
}

图形化界面
进行图形化界面的开发,有很多种方案.但是本质上都是来源于操作系统的支持.
首先操作系统得是图形化的,其次操作系统要给我们提供一些图形化编程的API.
当前的主流的操作系统(Windows,Linux,Mac,IOS,Android等)都是支持图形化界面的.
Java是一个跨平台的语言,会在JVM里针对系统的API进行封装.
我们在这里使用官方提供的图形化API,Java FX.
图形化界面的HelloWOrld
Java FX主要包含三个部分.
1.fxml文件,本质上是一个xml文件.这里的标签,属性,结构都是java fx定义好的.这里包含的信息就是一个窗口的界面是什么样子的,比如界面中的具体的元素,以及这些元素的尺寸,位置,样式等.
2.Controller类,把界面中的内容和Java代码关联起来.
3.入口类,程序的初始化操作,提供了一个main方法,让我们的程序能够运行起来.
先在resources目录下创建一个fxml文件.

此时可以发现在编辑器下方提供了一个标签页,Scence Builder.这个是Java官方,给Java FX提供的一个图形化界面设计器.可以借助设计器通过鼠标拖拽的方式生成界面的代码.
这个Scence Builder程序并非是Java FX必须的,手写fxml也是完全可以的.
首次使用,IDEA会从服务器自动加载对应的依赖,首次架子啊可能会消耗一定时间.
Scence Builder左侧有很多可以选择的界面元素.
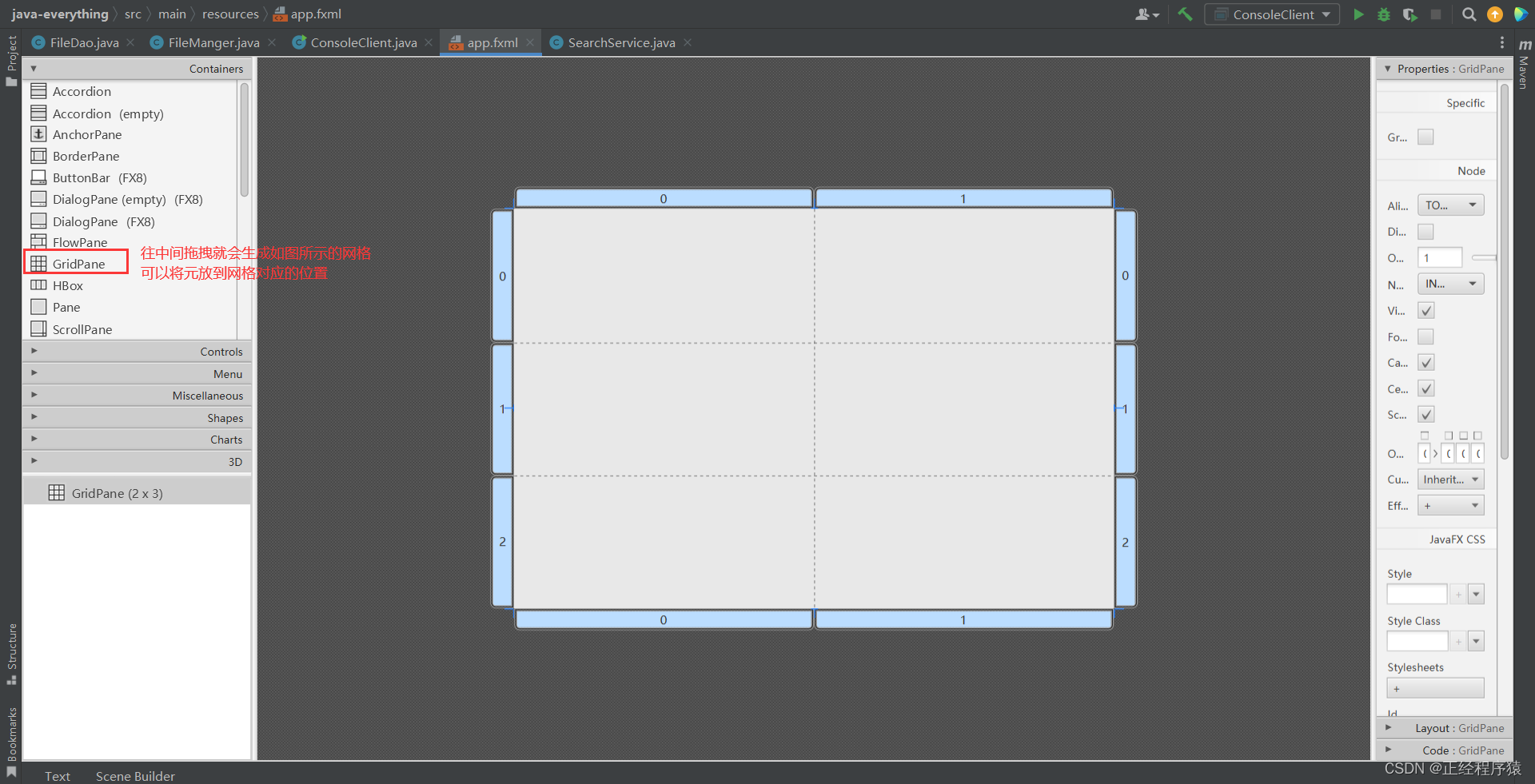
随着拖拽自动生成代码.
再在controls里面拖入一个label,可以放在任意一个网格内.


手动修改代码也会对Scence Builder中的内容产生影响.

编写完fxml,我们就可以写入口类了.
我们创建一个gui的包,里面是关于图形化界面的代码.
在gui包里创建一个GUIClient类,作为图形化界面的入口类.
package gui;import javafx.application.Application;
import javafx.fxml.FXMLLoader;
import javafx.scene.Parent;
import javafx.scene.Scene;
import javafx.stage.Stage;
//图形化界面的入口类
public class GUIClient extends Application {//start方法是程序启动的时候,立即执行的方法//通过这个方法进行程序的初始化操作@Overridepublic void start(Stage primaryStage) throws Exception {//加载fxml文件,把fxml文件里的内容,设置到舞台中Parent parent = FXMLLoader.load(GUIClient.class.getClassLoader().getResource("app.fxml"));primaryStage.setScene(new Scene(parent,1000,800));//设置标题primaryStage.setTitle("hello world");//帷幕拉开的操作//将场景显示出来primaryStage.show();}public static void main(String[] args) {//调用Javafx提供的launch方法来启动整个程序launch(args);}
}
让此类继承Application.Application是一个抽象类,我们需要重写start方法.
这个参数意义表示一个"舞台".相当于我们图形化程序的界面窗口.
Java FX把图形化界面程序,想象成是一个"话剧表演".
要先把舞台搭建好,才会有后续操作.
我们把fxml文件中的内容稍作修改,方便展示:

alignment="CENTER"表示居中.
执行main方法:

当前代码label标签里的内容是写死的,很多时候,我们要根据Java代码来动态的获取标签的内容,以展示给用户.
此时就需要Controller类,Controller类就作为界面和Java代码的桥梁.
package gui;import javafx.fxml.FXML;
import javafx.fxml.Initializable;
import javafx.scene.control.Label;import java.net.URL;
import java.util.ResourceBundle;public class GUIController implements Initializable {@FXMLprivate Label label;//程序在加载此类时,会自动调用到initialize方法@Overridepublic void initialize(URL location, ResourceBundle resources) {label.setText("hello Java FX");}
}
此类需要实现Initializable接口,重写initialize方法.
要想关联到对应的fxml文件还需要对fxml做出修改.

需要在GridPane中加入fx:controller,表明此网格组件是和gui包下的GUIController类相关联.
Label标签中需要加fx:id="label",表明此标签是和GUIController类里带有@fxml注解的label属性相关联.
此时在运行程序:标签的值已经发生变化了.

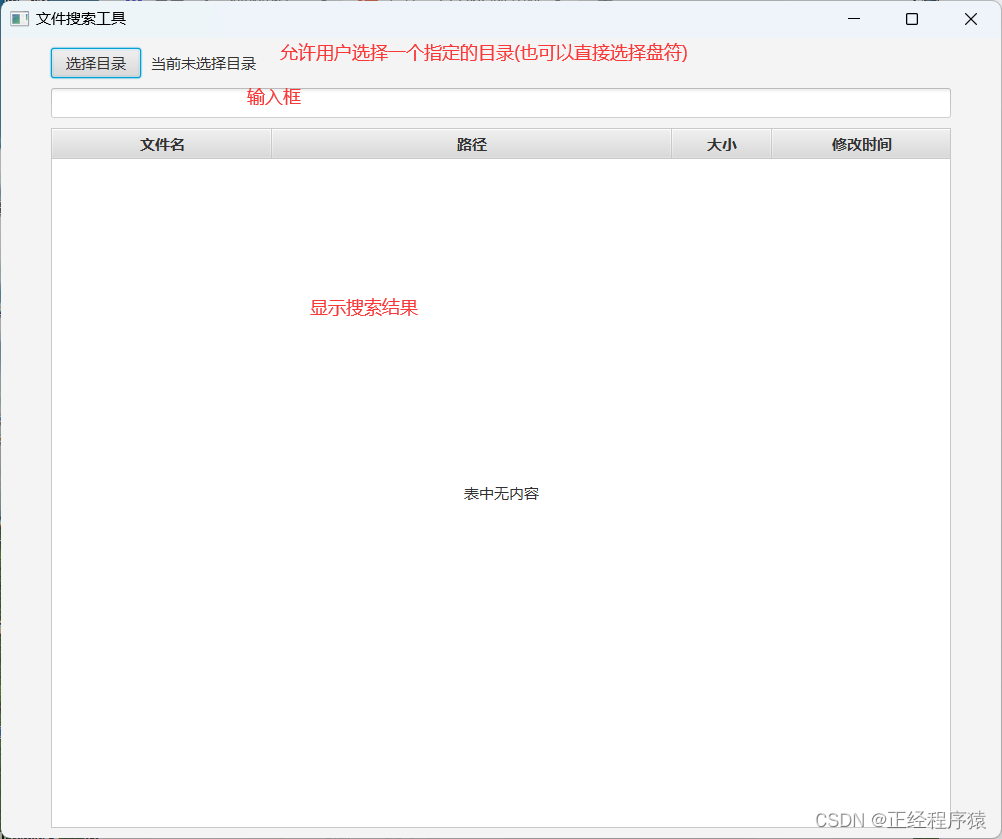
设计图形化界面
先考虑我们的图形化界面预期是什么样子的.
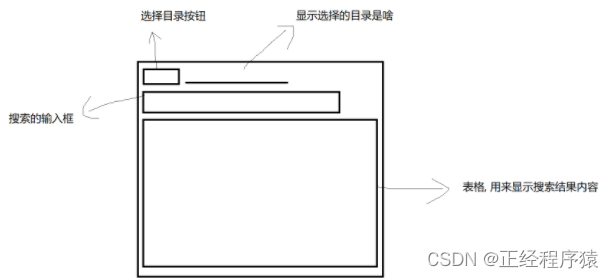
根据我们预期的效果去编写代码.
app.fxml的代码编写:
<?xml version="1.0" encoding="UTF-8"?><?import javafx.scene.control.*?>
<?import javafx.scene.layout.*?><?import javafx.geometry.Insets?>
<?import javafx.scene.control.cell.PropertyValueFactory?>
<GridPane fx:controller="gui.GUIController" fx:id="gridPane" vgap="10" alignment="CENTER" maxHeight="-Infinity" maxWidth="-Infinity" minHeight="-Infinity" minWidth="-Infinity" prefHeight="400.0" prefWidth="600.0" xmlns:fx="http://javafx.com/fxml/1" xmlns="http://javafx.com/javafx/8"><children><Button fx:id="button" onMouseClicked="#choose" prefWidth="90" text="选择目录" GridPane.rowIndex="0" GridPane.columnIndex="0"></Button><Label fx:id="label" text="当前未选择目录" GridPane.rowIndex="0" GridPane.columnIndex="0"><GridPane.margin><Insets left="100"></Insets></GridPane.margin></Label><TextField fx:id="textField" prefWidth="900" GridPane.rowIndex="1" GridPane.columnIndex="0"></TextField><TableView fx:id="tableView" prefWidth="900" prefHeight="700" GridPane.rowIndex="2" GridPane.columnIndex="0"><columns><TableColumn prefWidth="220" text="文件名"><cellValueFactory><PropertyValueFactory property="name"></PropertyValueFactory></cellValueFactory></TableColumn><TableColumn prefWidth="400" text="路径"><cellValueFactory><PropertyValueFactory property="path"></PropertyValueFactory></cellValueFactory></TableColumn><TableColumn prefWidth="100" text="大小"><cellValueFactory><PropertyValueFactory property="sizeText"></PropertyValueFactory></cellValueFactory></TableColumn><TableColumn prefWidth="100" text="修改时间"><cellValueFactory><PropertyValueFactory property="lastModifiedText"></PropertyValueFactory></cellValueFactory></TableColumn></columns></TableView></children>
</GridPane>
把按钮设置到第0行第0列.
onMouseClicked="#chose"添加一个鼠标点击事件,和GUIController中的chose对应,点击按钮自动调用此方法.
label也设置到第0行第0列,但是此时回合按钮重叠到一起,所以我们设置它的左边距为100px,因为按钮的宽度为90px.

TextField作为输入框,设置到第1行第0列.
TableView作为查询结果的列表集,来展示按照关键字查询到的结果.
TableView具体有多少行我们是不知道的,但是它的列数我们是清楚的.
所以我们将它的列给指定出来,并且每一列都绑定到filemeta中具体的属性,这一操作也需要和GUIController中tableView相互对应.
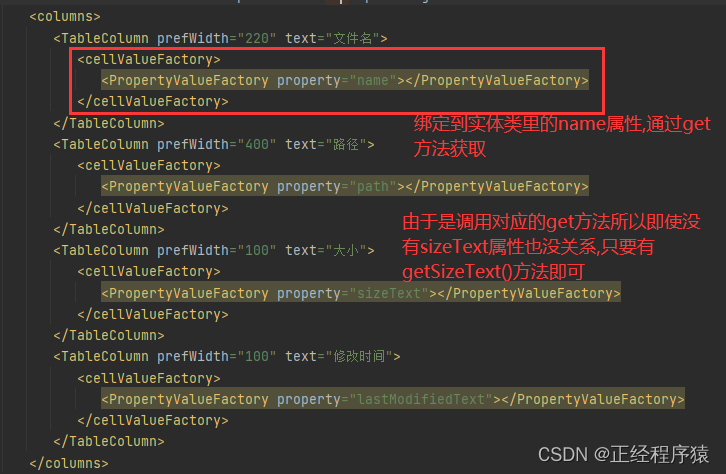
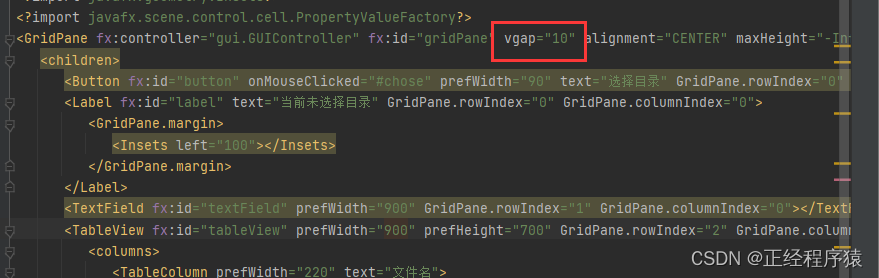
这样编写出来元素组件上下是没有边距的,所以我们在GridPane标签里设置vgap属性,vgap就表示网格里元素的上下边距,.
控制类的编写:
package gui;import dao.FileMeta;
import javafx.beans.value.ChangeListener;
import javafx.beans.value.ObservableListValue;
import javafx.beans.value.ObservableValue;
import javafx.collections.ObservableList;
import javafx.fxml.FXML;
import javafx.fxml.Initializable;
import javafx.scene.control.Button;
import javafx.scene.control.Label;
import javafx.scene.control.TableView;
import javafx.scene.control.TextField;
import javafx.scene.input.MouseEvent;
import javafx.scene.layout.GridPane;
import javafx.stage.DirectoryChooser;
import javafx.stage.Window;
import service.SearchService;import java.io.File;
import java.net.URL;
import java.util.List;
import java.util.ResourceBundle;public class GUIController implements Initializable {@FXMLprivate GridPane gridPane;@FXMLprivate Button button;@FXMLprivate Label label;@FXMLprivate TextField textField;@FXMLprivate TableView<FileMeta> tableView;private SearchService searchService;//程序在加载此类时,会自动调用到initialize方法@Overridepublic void initialize(URL location, ResourceBundle resources) {//给输入框加上一个监听器//textProperty()表示对输入框的内容进行监听textField.textProperty().addListener(new ChangeListener<String>() {@Overridepublic void changed(ObservableValue<? extends String> observable, String oldValue, String newValue) {//这个方法会在每次用户输入框内容的时候自动调用到//oldValue表示输入框被改之前的值//newValue表示输入框改完之后的值//此处要根据新的值,重新进行查询操作freshTable(newValue);}});}private void freshTable(String query) {//重新查询数据库,把查询结果设置到表格里if (searchService == null){System.out.println("searchService尚未初始化,不能查询!");return;}//先把之前的表格中旧的数据清楚//在添加新的数据//把之前的数据清除掉需要拿到tableView内部的集合类ObservableList<FileMeta> fileMetas = tableView.getItems();fileMetas.clear();List<FileMeta> results = searchService.search(query);//把查询到的结果添加到TableView中fileMetas.addAll(results);}//使用这个方法,作为鼠标点击事件的回调方法,这个方法里需要有一个MouseEvent对象.//这个对象里就包含了此次点击事件的相关信息public void choose(MouseEvent mouseEvent){//完成目录选择的工作//如何实现点击之后,弹出一个对话框来选择文件//JavaFX已经帮我们封装好了//JavaFX提供了一个DirectoryChooser类//我们只需要创建这个实例,并且让对话框显示出来//1.创建实例DirectoryChooser directoryChooser = new DirectoryChooser();//2.显示对话框Window window = gridPane.getScene().getWindow();File file = directoryChooser.showDialog(window);if (file == null){System.out.println("目录为空");return;}System.out.println(file.getAbsolutePath());//让用户选择的路径显示到label标签中label.setText(file.getAbsolutePath());//用户可能存在多次选择目录的情况//判定一下当前searchService是否是null,如果非空,说明现在不是程序首次扫描//此时就应该停止上次的扫描任务if (searchService!=null){searchService.shutDown();}//让用户选择路径,然后根据用户选择的路径进行扫描searchService = new SearchService();searchService.init(file.getAbsolutePath());}
}
在界面上弹出一个对话框,要明确这个对话框时哪个窗口弹出的,也就是说对话框要有一个父窗口,此时就需要程序的主窗口来作为对话框的父窗口.
为什么弹出对话框要指定父窗口呢?
这也是系统的一个规定,弹出对话框之后,必须要把对话框里的东西选好,然后才能据徐操作父窗口,如果会话框还没结束,此时父窗口是不可选中状态.这样的对话框我们也叫做模态对话框.
入口类的代码编写:
package gui;import javafx.application.Application;
import javafx.fxml.FXMLLoader;
import javafx.scene.Parent;
import javafx.scene.Scene;
import javafx.stage.Stage;
//图形化界面的入口类
public class GUIClient extends Application {//start方法是程序启动的时候,立即执行的方法//通过这个方法进行程序的初始化操作@Overridepublic void start(Stage primaryStage) throws Exception {//加载fxml文件,把fxml文件里的内容,设置到舞台中Parent parent = FXMLLoader.load(GUIClient.class.getClassLoader().getResource("app.fxml"));primaryStage.setScene(new Scene(parent,1000,800));//设置标题primaryStage.setTitle("文件搜索工具");//帷幕拉开的操作//将场景显示出来primaryStage.show();}public static void main(String[] args) {//调用Javafx提供的launch方法来启动整个程序launch(args);}
}