溧阳做网站的哪家好桂林seo
实现 ChatPDF & RAG:密集向量检索(R)+上下文学习(AG)
- RAG 是啥?
- 实现 ChatPDF
- 怎么优化 RAG?
RAG 是啥?
RAG 是检索增强生成的缩写,是一种结合了信息检索技术与语言生成模型的人工智能技术。
这种技术主要用于增强 LLM 的能力,使其能够生成更准确且符合上下文的答案,同时减少模型幻觉。
RAG通过将检索模型和生成模型结合起来,利用专有数据源的信息(比如多文档)来辅助文本生成。
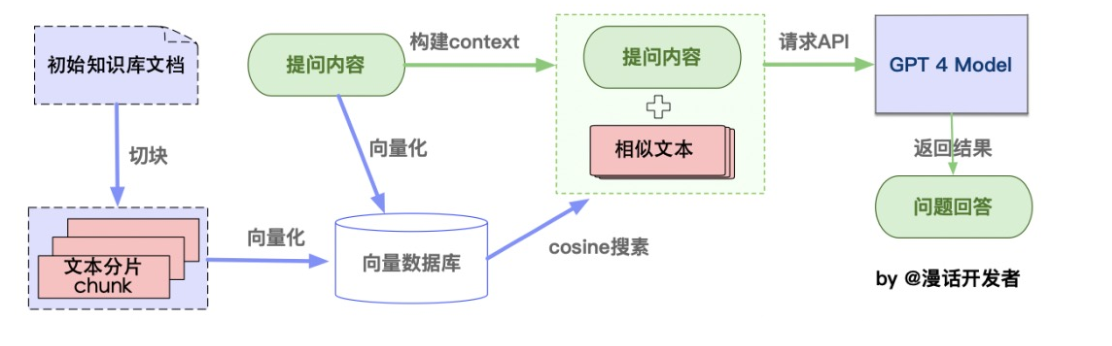
从本地文档加载到生成语言模型回答的整个流程。
-
文本分块:
- 加载文件:这一步骤涉及从本地存储读取文件。
- 读取文件:将读取的文件内容转换为文本格式。
- 文本分割:按照一定的规则(例如按段落、句子或词语)将文本分割成小块,便于处理。
-
向量化存储:
- 文本向量化:使用NLP技术(如TF-IDF、word2vec、BERT)将文本转换为数值向量。
- 存储到向量数据库:将文本的向量存储在向量数据库中,如使用FAISS进行高效存储和检索。
-
问句向量化:
- 这一步将用户的查询或问题转换为向量,使用的方法应与文本向量化相同,确保在相同的向量空间中比较。
-
在文本向量中匹配相似向量:
- 通过计算余弦相似度或欧式距离等,找出与查询向量最相似的顶部k个文本向量。
-
构建问题的上下文:
- 将匹配出的文本作为问题的上下文,与问题一起构成prompt,输入给语言模型。
-
生成回答:
- 将问题和其上下文提交给语言模型(如GPT系列),由模型生成相应的回答。
通用 RAG 就是如此,最终目的是提供精确和相关的信息回答。
实现 ChatPDF
实现 RAG 步骤有很多步,涉及的知识点也很多,直接上已实现的开源项目,不用深入理解里面每个知识点,能用就行。
开源项目:https://github.com/chatchat-space/Langchain-Chatchat
这个项目是 Apache-2.0 license,开源可商用。
conda create -n chatpdf python==3.11.7 # 创建虚拟环境# 拉取仓库
$ git clone https://github.com/chatchat-space/Langchain-Chatchat.git# 进入目录
$ cd Langchain-Chatchat# 安装全部依赖
$ pip install -r requirements.txt
$ pip install -r requirements_api.txt
$ pip install -r requirements_webui.txt # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。# 模型下载
$ git lfs install
$ git clone https://huggingface.co/THUDM/chatglm4-9b
$ git clone https://huggingface.co/BAAI/bge-large-zh# 初始化知识库和配置文件
$ python copy_config_example.py
$ python init_database.py --recreate-vs# 启动项目
$ python startup.py -a
这个自己实现的 ChatPDF 功能:
- 解读文档,任何领域任何书籍任何专业,都能让人看懂
- 使用RAG,回答是检索不是生成,极大减少幻觉
- 能多文档,不会被长上下文限制(200k)
- 本地部署的模型,不是调用api,不会泄露数据
怎么优化 RAG?
方案1:不同领域下,通用 RAG 方案效果也不好,一般需要按场景定制优化的。
- 比如医学领域,用户搜索感冒,但医学数据库里面是风热流感,关键词不匹配就造成检索错位,只能得到通用信息
- 分解子问题查询 + 多步查询
方案2:通用 RAG 在文本分块的时候,通常只是粗暴的把 pdf 划分为 1500 块,很多关联的上下文被迫分隔。
- 最好是按照规则分块,而不是固定一个块,比如按标题(一级标题、二级标题、三级标题…),这样整个子块的内容都完整
- 再链接每个子块和父文档,复现上下文的相关性
- 如果那个作者标题写法不好,可以使用语义分割(阿里语义分割模型SeqModel)
方案3:PDF 解析时错漏很多信息,比如老年糖尿病标准变成了糖尿病标准,这个很影响效果
- 不能使用 pdf 加载器自动拆分,而是要手动精细拆分,再加上多个选项排序,得到最精准的那个
方案4:词嵌入模型没有经过微调,比如我的数据都是医学的,使用的 embedding 模型 没有经过医学微调,很多名词、概念把握不清,只能捕捉到一些通用的医学术语和语法结构
- 尝试更多embedding模型,获得更精确的检索结果。如:piccolo-large-zh 或 bge-large-zh-v1.5、text2vec、M3E、bge、text-embedding-3 等,或者自己微调词嵌入模型
方案5:如果涉及大量文档,使用 pgVector - 高性能向量数据库引擎,如果存在较多相似的内容,可以考虑分类存放数据,减少冲突的内容
方案6:改进传统 RAG 算法
- 比如动态检索和重排序
- 比如multihop多跳检索
方案7:基于文档中的表格问题,通用 RAG 这块效果不好。
- 优先转为HTML、xml 格式,也可以 OCR
方案8:引入动态 RAG
- 静态 RAG,使用提示词和已向量的数据,检索交互
- 动态 RAG,一边交互,一边把交互内容,生成搜索词,会呼吸的RAG,实现自主更新