宁德建设银行网站百度明星人气排行榜
前言
文本自动生成是自然语言处理领域的一个重要研究方向,实现文本自动生成也是人工智能走向成熟的一个重要标志。文本自动生成技术极具应用前景。
例如,文本自动生成技术可以应用于智能问答与对话、机器翻译等系统,实现更加智能和自然的人机交互;也可以通过文本自动生成系统替代编辑实现新闻的自动撰写与发布,最终将有可能颠覆新闻出版行业;该项技术甚至可以用来帮助学者进行学术论文撰写,进而改变科研创作模式。
按照不同的输入划分,文本自动生成可包括文本到文本的生成(text-to-text generation)、意义到文本的生成(meaning-to-text generation)、数据到文本的生成(data-to-text generation)以及图像到文本的生成(image-to-text generation)等。上述每项技术均极具挑战性,在自然语言处理与人工智能领域均有相当多的前沿研究,近几年业界已产生了若干具有国际影响力的成果与应用。
本文主要简单介绍文本生成中最为成熟的领域的——文本到文本的生成的一些常用算法,最后实操部分则是使用中文数据训练Char-RNN
模型生成中文文本。
文本生成算法
首先,啥是文本生成,简单来说,就是输入一段文本,经过自然语言模型之后,生成一段新的文本,如下图所示
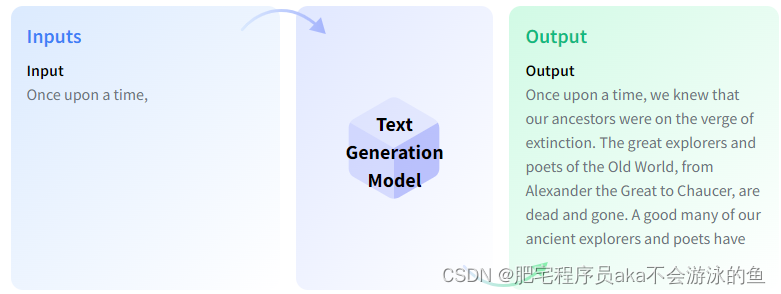
这便是文本自动补全场景下的文本生成,这种应用场景多见于智能问答与对话;如果是机器翻译场景下的文本生成,那模型输入则是需要被翻译的文本,模型输出是翻译后的文本语言;同样的,文本摘要,则更好理解,就是输入一段文本,模型输出这段文本的概括文本。
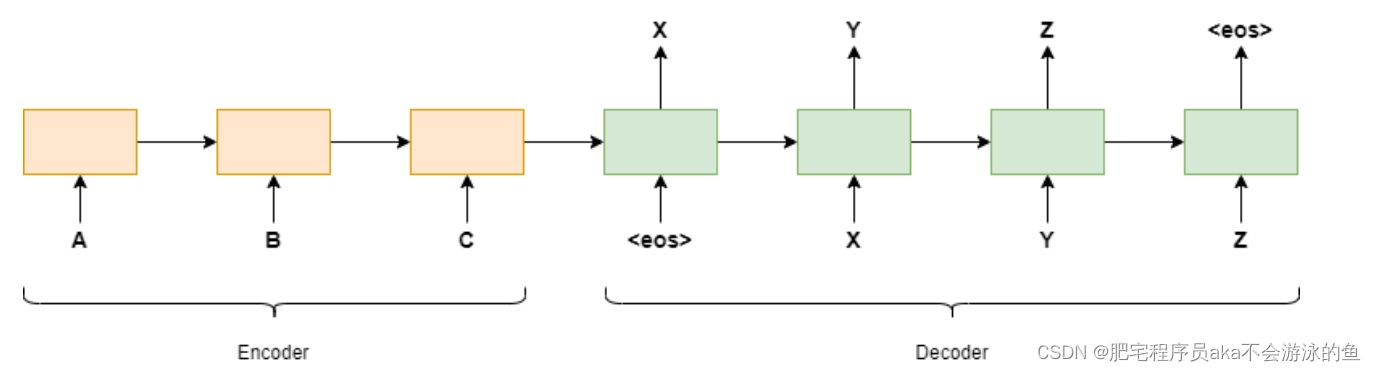
在很长一段时间里,文本生成主要都基于Seq2Seq模型,所谓的Seq2Seq模型就是使用上一个时刻的值来预测下一个时刻的值,两个常用的模型是GRU和LSTM。然而,用 RNN 生成的文本远非也会有一些问题,比如,RNN模型有时候会输出一些莫名其妙的文本,有时还包括一些基本的拼写错误,而其中一个时刻的错误输出,则会让整段文本的输出变得不可用。此外,在推理过程中的无法并行化也是RNN模型在处理序列数据时的一个致命缺陷。
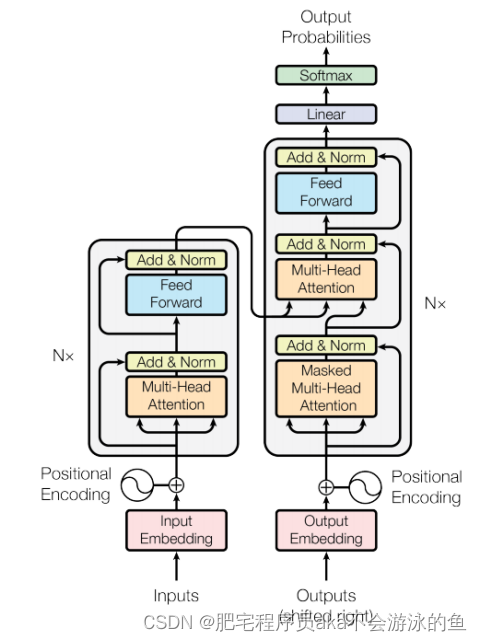
后来,为了解决RNN模型的缺陷,谷歌在2017年发布了一篇经典文章"Attention Is All You Need", 文章中提出了Transformer模型。Transformer是包含了自注意力机制、全连接层的同样带有编码器和解码器的全新的网络结构,同时由于Transformer模型中没有包含RNN网络结构,使其可以并行运算,大大提升了模型的训练和推理时间。当然,模型的参数量也比RNN提升了数倍,模型拟合能力也得到了大大的提升。
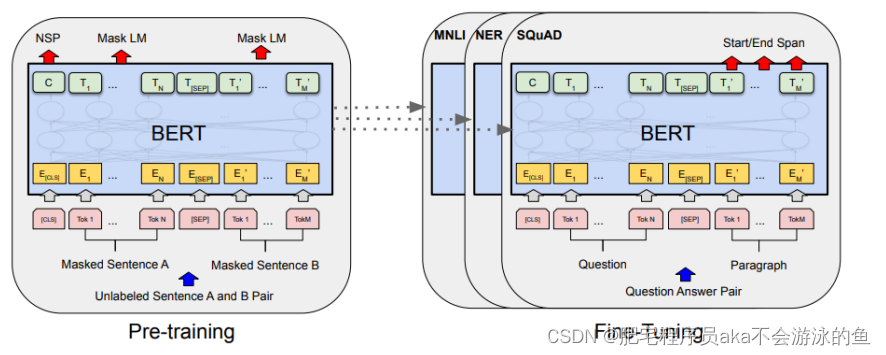
再后来随着深度学习领域的发展,业界提出了更多更大的模型来解决NLP领域的问题,当然,这里也包括了文本生成这一领域。随着BERT、GPT-2、GPT-3等等大模型的提出,使得文本生成的开发可以使用少量场景数据在大模型的基础上做fine-tuned,这样也可以得到远超过简单的Seq2Seq模型的效果。
当然,文本生成领域内容太多,所涉及的算法也很复杂,笔者这里提到的只是一些常规的模型和技术方法,对其他的模型和算法感兴趣的可以参考文末的参考文章继续深入阅读。
中文char-rnn文本生成训练demo
char-rnn之于文本生成领域的地位,与手写mnist之一图像分类领域地位一样,可以说,就是一个入门级别的模型,就是使用RNN模型,输入一个字符,输出一个字符,最后要么达到字数限制,要么输出结束字符,这样就完成文本生成的任务。
这里的中文char-rnn,训练数据使用的中文小说,使用结巴分词将语料进行预处理,然后将分词的结果再进行Embedding编码。
数据预处理
whole = open('text/白夜行.txt', encoding='utf-8').read()
all_words = list(jieba.cut(whole, cut_all=False)) # jieba分词
words = sorted(list(set(all_words)))
word_indices = dict((word, words.index(word)) for word in words)maxlen = 30
epoch_num = 100
class TextTensorDataset(Dataset):def __init__(self, all_words, maxlen, word_indices):sentences = []next_word = []for i in range(0, len(all_words) - maxlen):sentences.append(all_words[i: i + maxlen])next_word.append(all_words[i + maxlen])print('提取的句子总数:', len(sentences))self.inputs = np.zeros((len(sentences), maxlen), dtype='float32') # 先将每个inputs切成30个词的句子列表,然后将句子中的词转化成index索引self.labels = np.zeros((len(sentences)), dtype='float32')for i, sentence in enumerate(sentences):for t, word in enumerate(sentence):self.inputs[i, t] = word_indices[word]self.labels[i] = word_indices[next_word[i]]def __getitem__(self, item):# x = np.expand_dims(self.inputs[item], axis=0)# y = np.expand_dims(self.labels[item], axis=0)return self.inputs[item], self.labels[item]def __len__(self):return len(self.inputs)模型定义
class LSTM(torch.nn.Module):def __init__(self, hidden_size1, hidden_size2, vocab_size, input_size, num_layers):super().__init__()self.embed = torch.nn.Embedding(vocab_size, input_size, max_norm = 1)self.lstm1 = torch.nn.LSTM(input_size, hidden_size1, num_layers, batch_first=True, bidirectional=True)self.lstm2 = torch.nn.LSTM(hidden_size1*2, hidden_size2, num_layers, batch_first=True, bidirectional=True)self.dropout = torch.nn.Dropout(0.1)self.line = torch.nn.Linear(hidden_size2 * maxlen * 2, vocab_size)self.softmax = torch.nn.Softmax(dim=1)def forward(self, x):x = self.embed(x) output1, _ = self.lstm1(x) output, _ = self.lstm2(output1) out_d_reshaped = output.reshape(output.shape[0], (output.shape[1] * output.shape[2]) )line_o = self.line(out_d_reshaped)pred = self.softmax(line_o)#print(pred.shape)return pred
模型使用了两个双向的LSTM,然后再接了一个全连接层,整体都比较简单,没有什么可以详细阐述的
模型训练
hidden_size1, hidden_size2, vocab_size, input_size, num_layers = 256, 128, len(words), 128, 2model = LSTM(hidden_size1, hidden_size2, vocab_size, input_size, num_layers).to(device)loss_function = torch.nn.NLLLoss().to(device)optimizer = torch.optim.RMSprop(model.parameters(), lr=3e-3)mydataset = TextTensorDataset(all_words, maxlen, word_indices)train_loader = DataLoader(mydataset, batch_size=1024, shuffle=True)# training
model.train()
h_state = Nonefor epoch in range(epoch_num):total_loss = 0items = 0for batch_x, batch_label in (train_loader):x = Variable(torch.LongTensor(batch_x.numpy())).cuda()#torch.Size([1024, 30, 1])pred = model(x)pred = torch.log(pred.view(-1, vocab_size) + 1e-20) #print('pred shape ', pred.shape)target = Variable(batch_label.view(-1)).cuda()#print('target shape ', target.shape)loss = loss_function(pred, target.long()) optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()items += 1print('Epoch {}, Step {} Train Loss {}'.format(epoch, items, loss.item() ) )#save model every 10 epochesif epoch % 10 == 0:if not os.path.exists("./new_trained"):os.makedirs("./new_trained")directory = './new_trained/rnn_novel'+str(epoch)+'.pkl'torch.save(model, directory)
预测代码
def write_words(model, word_num, begin_sentence):gg = begin_sentence[:30]print(''.join(gg), end='/// ')for _ in range(word_num):sampled = np.zeros((1, maxlen)) for t, char in enumerate(gg):sampled[0, t] = word_indices[char]x = Variable(torch.LongTensor(sampled)).cuda()preds = model(x)next_word = words[np.argmax(preds.data.cpu().numpy())]gg.append(next_word)gg = gg[1:]sys.stdout.write(next_word)sys.stdout.flush()begin_sentence = whole[50003: 50100]
print("初始句:", begin_sentence[:30])
begin_sentence = list(jieba.cut(begin_sentence, cut_all=False))write_words(model, 300, begin_sentence)
这里为了方便简单,在模型完成训练之后,即刻进行模型预测,模型预测的效果如下:

参考
运用深度学习进行文本生成
torch.nn.Embedding使用详解
【pytorch】关于Embedding和GRU、LSTM的使用详解
Pytorch损失函数torch.nn.NLLLoss()详解
Text Generation
Char RNN原理介绍以及文本生成实践
MODERN METHODS OF TEXT GENERATION
文本自动生成研究进展与趋势