那个网站推作者自己搭建网站
Hadoop入门系列(四) HDFS的使用与编程
内容
- 使用Hadoop Shell命令操作hdfs文件系统,熟悉分布式文件系统及操作命令。
- 配置Maven及使用Maven构建的Hadoop工程项目。
- 使用Hadoop的JAVA api操作hdfs文件系统。
HDFS的使用与编程
HDFS基本命令
mkdir创建文件目录
hadoop fs -mkdir -p /Software/hadoop/
hadoop fs -mkdir -p hdfs://localhost:9000/Software/Java/
put上传文件
hadoop fs -put ~/hadoop-2.8.3.tar.gz /Software/hadoop/
hadoop fs -put ~/jdk-8u172-linux-x64.rpm /Software/Java/
hadoop fs -put /usr/local/hadoop2/README.txt /
ls显示目录结构
hadoop fs -ls /Software/
chmod修改文件权限
hadoop fs -chmod 600 /Software/hadoop
hadoop fs -ls /Software/
rm删除文件
hadoop fs -rm /Software/Java/*
rmdir删除目录
hadoop fs -rmdir /Software/Java
get下载文件
hadoop fs -get /README.txt ~
ls -l ~
cat显示文件内容
hadoop fs -cat /README.txt
cp复制文件
hadoop fs -cp /Software/hadoop/hadoop-2.8.3.tar.gz /Software
mv移动文件
hadoop fs -mkdir -p /input
hadoop fs -mv /README.txt /input
使用Java API 访问HDFS文件系统
ApacheMaven是一套软件工程管理和整合工具。基于工程对象模型(POM)的概念
通过一个中央信息管理模块,Maven能够管理项目的构建、发布、报告和文档。即使常用
的Eclipse这样的JavaIDE开发环境,其内部也是通过Maven管理Java项目的。在编程时,
通过Maven的包管理功能可以自动下载程序所需要的jar包,使得开发过程十分方便。
MAVEN 的安装与配置
这里的安装包我已经事先准备好了,所以可以直接从sudo tar开始执行
cd
curl -O http://mirrors.shu.edu.cn/apache/maven/binaries/apache-maven-3.2.2-bin.tar.gz
sudo tar -xvf ./apache-maven-3.2.2-bin.tar.gz -C /usr/local/
echo 'export MAVEN_HOME=/usr/local/apache-maven-3.2.2
> export MAVEN_OPTS="$MAVEN_OPTS -Xms256m -Xmx512m -XX:ReservedCodeCacheSize=64m"
> export PATH=${PATH}:${MAVEN_HOME}/bin' > ~/maven.sh
sudo mv ~/maven.sh /etc/profile.d/
source /etc/profile.d/maven.sh
mvn --version


使用 Maven 阿里云中央仓库
由于Maven 缺省使用国外的中央仓库,使得下载依赖包时十分缓慢,因此,需要将中央仓库配置为国内的阿里云中央仓库。
打开maven的配置文件
sudo gedit /usr/local/apache-maven-3.2.2/conf/settings.xml

<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf></mirror></mirrors>

使用 Maven 构建Java项目
在本实验中我们将要开发一个读取并显示hdfs文件系统根目录下的README.txt文件
的程序。
为此我们采用Maven构建Java项目
使用Maven只要学习很少的命令就可以创
建和管理Java项目
在命令行下执行以下代码,以创建Java项目。
cd ~
mvn archetype:generate -DgroupId=edu.dufe.hdfstest -DartifactId=HdfsCatREADME -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
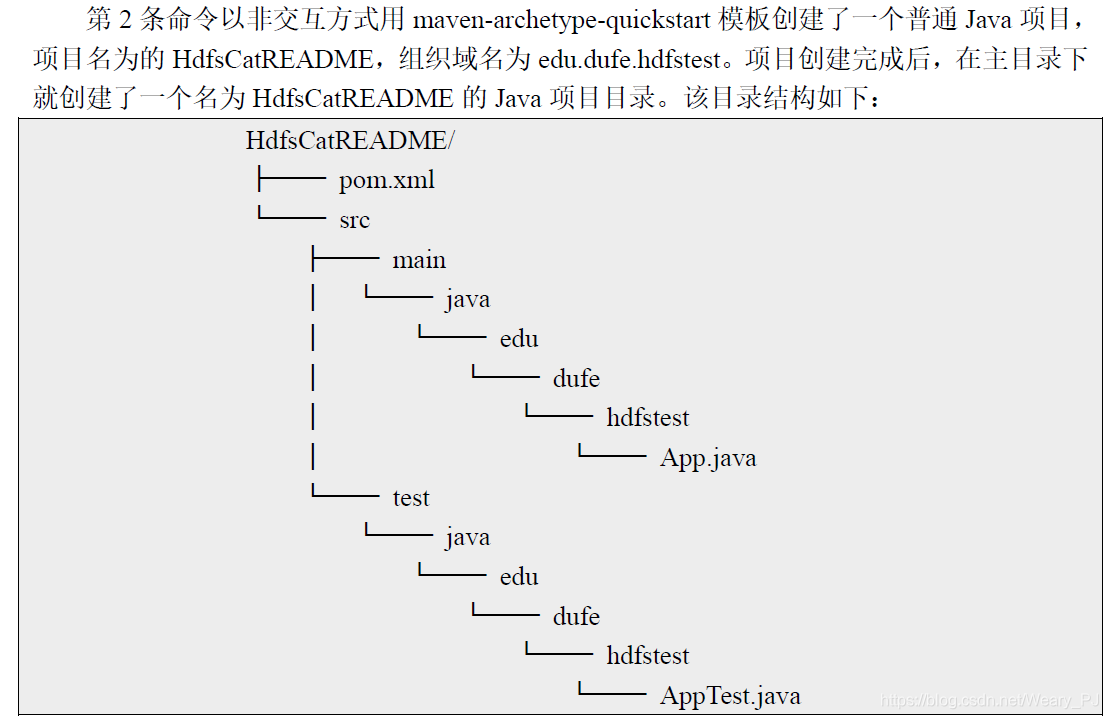
我们可以使用tree 命令查看一下目录的结构
**如果没有下载过tree命令的用下面的语句下载**
sudo yum -y install tree
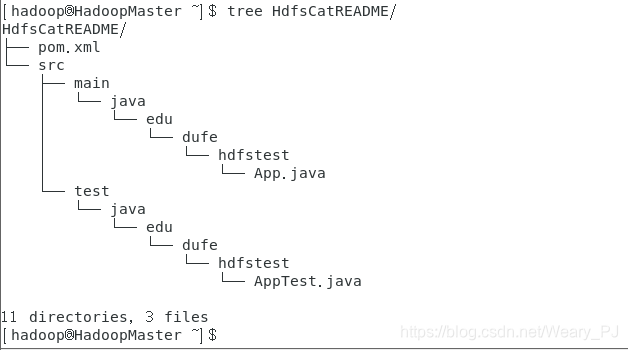
上图就是刚刚创建的java项目的结构了
项目目录下pom.xml文件,它描述了整个项目的信息,一切从目录结构,项目的插件,
项目依赖,如何构建这个项目等。App.java是项目源程序AppTest.java是项目测试源程序。
在本实验中我们将要开发一个读取并显示hdfs文件系统根目录下的README.txt文件
的程序因此需要将App.java名称重命名为HdfsCatREADME.java并在pom.xml中添加与
hadoop2.8.3的依赖项。为此执行以下命令。
修改源程序文件名
cd ~/HdfsCatREADME/src/main/java/edu/dufe/hdfstest/
mv ./App.java ./HdfsCatREADME.java
cd ~/HdfsCatREADME
然后在CentOS7桌面上,使用gedit打开HdfsCatREADME/pom.xml文件。将以下红色内
容添加到文件的对应位置处。

gedit ~/HdfsCatREADME/pom.xml
下面是整个文件修改后的内容
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>edu.dufe.hdfstest</groupId><artifactId>HdfsCatREADME</artifactId><packaging>jar</packaging><version>1.0-SNAPSHOT</version><name>HdfsCatREADME</name><url>http://maven.apache.org</url><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.8.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.8.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.8.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.8.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-auth</artifactId><version>2.8.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope></dependency></dependencies><build><finalName>HdfsCatREADME</finalName><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><version>2.4</version><configuration><archive><manifest><mainClass>edu.dufe.hdfstest.HdfsCatREADME</mainClass><addClasspath>true</addClasspath><classpathPrefix>lib/</classpathPrefix></manifest><manifestEntries><Class-Path>lib/slf4j-api-1.7.13.jar</Class-Path></manifestEntries></archive></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-dependency-plugin</artifactId><executions><execution><id>copy</id><phase>package</phase><goals><goal>copy-dependencies</goal></goals><configuration><outputDirectory>${project.build.directory}/lib</outputDirectory></configuration></execution></executions></plugin></plugins></build>
</project>
接下里编写Java源程序
gedit src/main/java/edu/dufe/hdfstest/HdfsCatREADME.java
package edu.dufe.hdfstest;import java.io.IOException;
import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; public class HdfsCatREADME
{public static void main(String[] args) { try { String dsf = "hdfs://127.0.0.1:9000/README.txt"; Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(dsf),conf); FSDataInputStream hdfsInStream = fs.open(new Path(dsf)); byte[] ioBuffer = new byte[1024]; int readLen = hdfsInStream.read(ioBuffer); while(readLen!=-1) { System.out.write(ioBuffer, 0, readLen); readLen = hdfsInStream.read(ioBuffer); } hdfsInStream.close(); fs.close(); } catch (IOException e) { e.printStackTrace(); } }
}
使用 Maven 编译打包Java项目
项目开发完成后,我们就可以编译、打包项目了,为此执行以下命令。
cd ~/HdfsCatREADME
mvn clean compile
mvn clean package
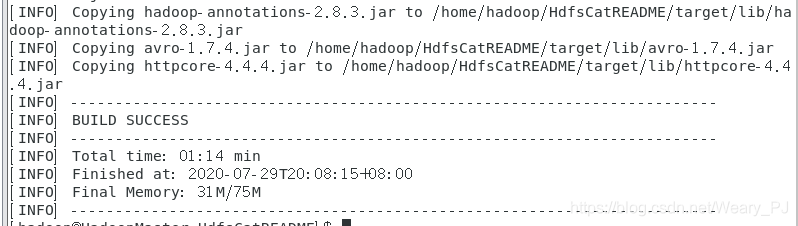
当命令执行后,显示出[INFO] BUILD SUCCESS内容时,说明编译打包成功。这里
在~/HdfsCatREADME目录下就会多出一个target的文件夹, 并在此文件夹下有编译打包好
的目标程序 HdfsCatREADME.jar
- 如果编译失败,则有可能是源程序有错误,请根据出错
提示,仔细核对源程序是否正确。 - 如果打包失败,请检查pom.xml文件是否正确。
下图是成功的结果
执行程序
cd ~/HdfsCatREADME
java -jar ./target/HdfsCatREADME.jar #执行程序
这里我产生了如下的报错
Call From HadoopMaster/192.168.206.15 to localhost:9000 failed on connection exception: java.net.ConnectException: 拒绝连接;
仔细一看 拒绝连接,是因为我重启虚拟机之后尚未启动hadoop 这里只需要start-dfs.sh就可以了
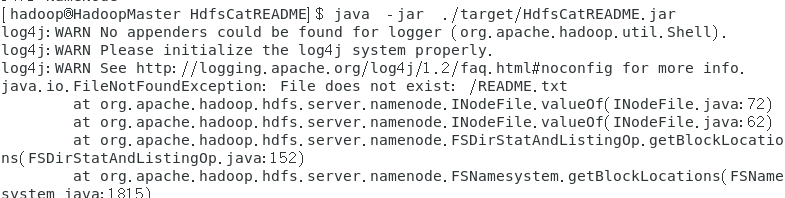
又报错了,这次是README.txt不存在,简单的检查一下
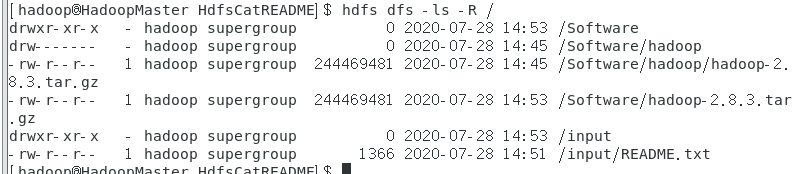
因为之前Java里面定义的是根目录下的,这里就简单的copy一份就好了

这里的命令在文章开头就讲了,所以遇到错误不要慌

成功读出结果
更多关于Java操作HDFS的实例 可以看东财实验4PDF的附录
使用Python 访问HDFS文件系统
安装python及hdfs包
注意要先执行下面命令,不然可能会显示python34不存在
官方的rpm repository提供的rpm包往往是很滞后的,装上了 epel 之后,就相当于添加了一个第三方源
yum install epel-release
安装python与hdfs包
sudo yum install python34 #安装python3
sudo yum install python34-pip #安装包管理工具
sudo pip3.4 install hdfs #安装hdfs包
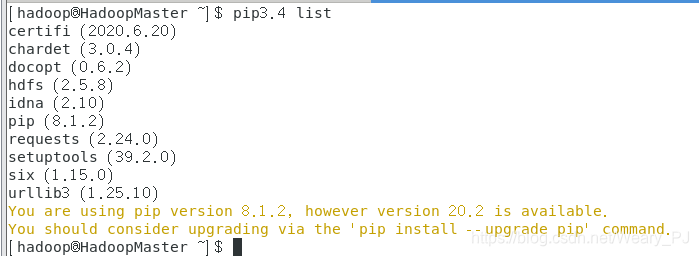
可以看到我们已经安装了hdfs,下面的提示是警告你升级pip的,按它说的执行就好了
创建 hdfs 连接实例
python的操作非常简单
先创建client连接
然后通过client对象来操作hdfs ,下面的代码创建了文件夹并且 列举了根目录的内容
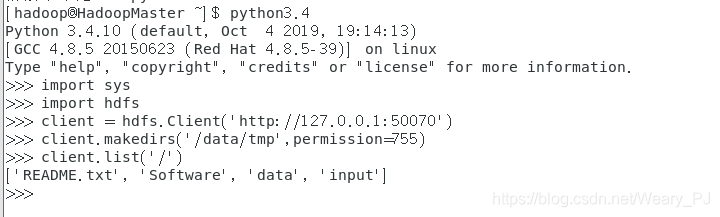
permission参数是对要创建的文件夹设置权限
#创建hdfs连接实例
import sys
import hdfs
client = hdfs.Client("http://127.0.0.1:50070")
#创建文件目录并列表
client.makedirs("/data/tmp",permission=755)
client.list("/")
更多python操作的细节 可搜索百度