军事最新新闻播报青岛网络优化代理
文章目录
- Hive数据仓库——UDF、UDTF
- UDF:一进一出
- 案例一
- 创建Maven项目,并加入依赖
- 编写代码,继承org.apache.hadoop.hive.ql.exec.UDF,实现evaluate方法,在evaluate方法中实现自己的逻辑
- 打成jar包并上传至Linux虚拟机
- 在hive shell中,使用 ```add jar 路径```将jar包作为资源添加到hive环境中
- 使用jar包资源注册一个临时函数,fxxx1是你的函数名,'MyUDF'是主类名
- 使用函数名处理数据
- 案例二
- 编写代码,继承org.apache.hadoop.hive.ql.exec.UDF,实现evaluate方法,在evaluate方法中实现自己的逻辑
- 打成jar包并上传至Linux虚拟机
- 在hive shell中,使用 ```add jar 路径```将jar包作为资源添加到hive环境中
- 使用jar包资源注册一个临时函数,fxxx1是你的函数名,'MyUDF'是主类名
- 使用函数名处理数据
- UDTF:一进多出
- 方法一:使用 explode+split
- 方法二:自定义UDTF
- 案例一
- 案例 二
Hive数据仓库——UDF、UDTF
UDF:一进一出
案例一
创建Maven项目,并加入依赖
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>1.2.1</version>
</dependency>
编写代码,继承org.apache.hadoop.hive.ql.exec.UDF,实现evaluate方法,在evaluate方法中实现自己的逻辑
package com.liangzai.UDF;import org.apache.hadoop.hive.ql.exec.UDF;public class MyUDF extends UDF {// 自定义UDF 需要继承UDF类,实现evaluate方法public String evaluate(String gender) {// 男 女String resStr = "";resStr = gender.replace("男","boy");resStr = resStr.replace("女","girl");return resStr;}
}
打成jar包并上传至Linux虚拟机

在hive shell中,使用 add jar 路径将jar包作为资源添加到hive环境中
add jar /usr/local/soft/jars/Hive-1.0.jar;

使用jar包资源注册一个临时函数,fxxx1是你的函数名,'MyUDF’是主类名
create temporary function my_udf as 'com.liangzai.UDF.MyUDF';
使用函数名处理数据
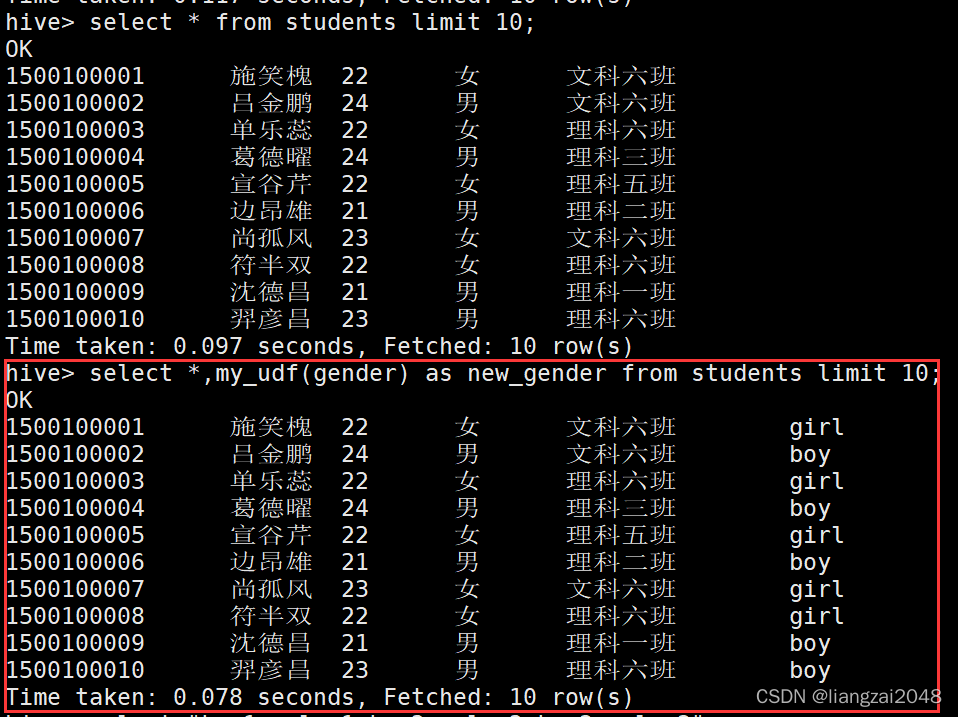
select my_udf(gender) as new_gender from students limit 10;
select *,my_udf(gender) as new_gender from students limit 10;
案例二
编写代码,继承org.apache.hadoop.hive.ql.exec.UDF,实现evaluate方法,在evaluate方法中实现自己的逻辑
package com.liangzai.UDF;import org.apache.hadoop.hive.ql.exec.UDF;public class MyUDF1 extends UDF {public String evaluate(String clazz) {// 自定义UDF 需要继承UDF类,实现evaluate方法// 班级String resStr = "";resStr = clazz.replace("一","1");resStr = resStr.replace("二","2");resStr = resStr.replace("三","3");resStr = resStr.replace("四","4");resStr = resStr.replace("五","5");resStr = resStr.replace("六","6");return resStr;}
}
打成jar包并上传至Linux虚拟机

在hive shell中,使用 add jar 路径将jar包作为资源添加到hive环境中
add jar /usr/local/soft/jars/Hive-1.0.jar;
使用jar包资源注册一个临时函数,fxxx1是你的函数名,'MyUDF’是主类名
create temporary function my_udf as 'com.liangzai.UDF.MyUDF1';

使用函数名处理数据
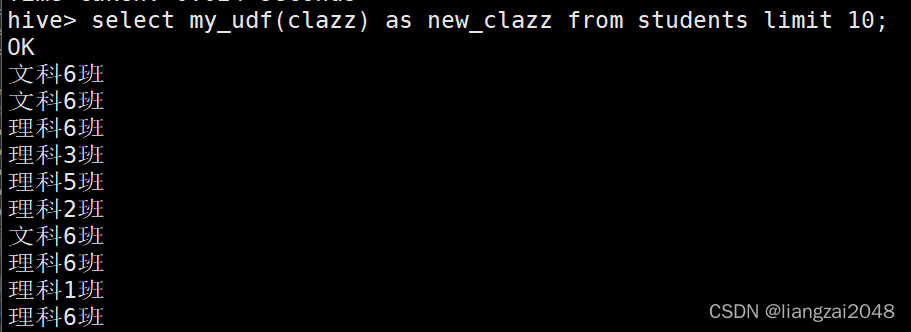
select my_udf(clazz) as new_clazz from students limit 10;
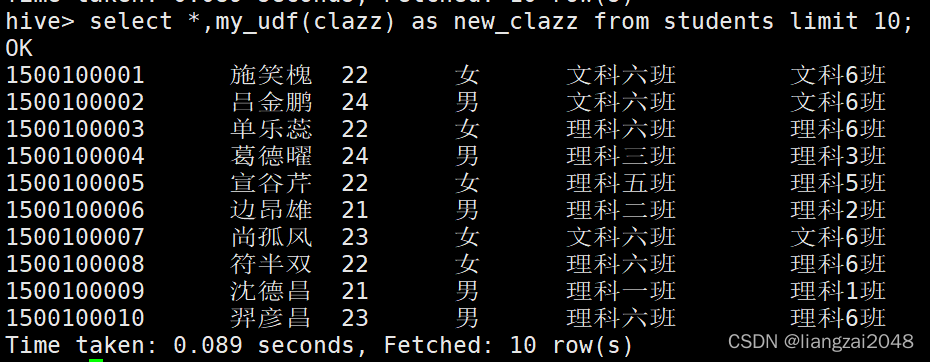
select *,my_udf(clazz) as new_clazz from students limit 10;
UDTF:一进多出
方法一:使用 explode+split
select "key1:value1,key2:value2,key3:value3";
// 结果
key1:value1,key2:value2,key3:value3select split("key1:value1,key2:value2,key3:value3",",");
// 结果
["key1:value1","key2:value2","key3:value3"]select explode(split("key1:value1,key2:value2,key3:value3",","));
// 结果
key1:value1
key2:value2
key3:value3select t1.kv from (select explode(split("key1:value1,key2:value2,key3:value3",",")) as kv) t1;
// 结果
key1:value1
key2:value2
key3:value3select split(t1.kv,":")[0] as key,split(t1.kv,":")[1] as value from (select explode(split("key1:value1,key2:value2,key3:value3",",")) as kv) t1;
// 结果
key1 value1
key2 value2
key3 value3
方法二:自定义UDTF
案例一
- 代码
package com.liangzai.UDF;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;public class MyUDTF extends GenericUDTF {@Override// initialize方法,会在UDTF被调用的时候执行一次public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {ArrayList<String> fieldNames = new ArrayList<String>();ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();fieldNames.add("col1");fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);fieldNames.add("col2");fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);}@Overridepublic void process(Object[] args) throws HiveException {// "key1:value1,key2:value2,key3:value3"for (Object arg : args) {String[] kvSplit = arg.toString().split(",");for (String kv : kvSplit) {String[] splits = kv.split(":");String key = splits[0];String value = splits[1];ArrayList<String> kvList = new ArrayList<>();kvList.add(key);kvList.add(value);forward(kvList);}}}@Overridepublic void close() throws HiveException {}
}
- 添加jar资源:
add jar /usr/local/soft/jars/Hive-1.0.jar;
- 注册udtf函数:
create temporary function my_udtf as 'com.liangzai.UDF.MyUDTF';
- SQL:
select my_udtf("key1:value1,key2:value2,key3:value3","key1:value1,key2:value2,key3:value3");

案例 二
- 数据
create table udtfData(id string,col1 string,col2 string,col3 string,col4 string,col5 string,col6 string,col7 string,col8 string,col9 string,col10 string,col11 string,col12 string
)row format delimited fields terminated by ',';
a,1,2,3,4,5,6,7,8,9,10,11,12
b,11,12,13,14,15,16,17,18,19,20,21,22
c,21,22,23,24,25,26,27,28,29,30,31,32
- 代码
package com.liangzai.UDF;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;public class MyUDTF2 extends GenericUDTF {@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {ArrayList<String> fieldNames = new ArrayList<String>();ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();fieldNames.add("hour");fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);fieldNames.add("value");fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);}@Overridepublic void process(Object[] args) throws HiveException {int hour = 0;for (Object arg : args) {String value = arg.toString();ArrayList<String> hourValueList = new ArrayList<>();hourValueList.add(hour+"时");hourValueList.add(value);forward(hourValueList);hour += 2;}}@Overridepublic void close() throws HiveException {}
}
- 添加jar资源:
add jar /usr/local/soft/jars/Hive-1.0.jar;
- 注册udtf函数:
create temporary function my_udtf as 'com.liangzai.UDF.MyUDTF2';
- SQL:
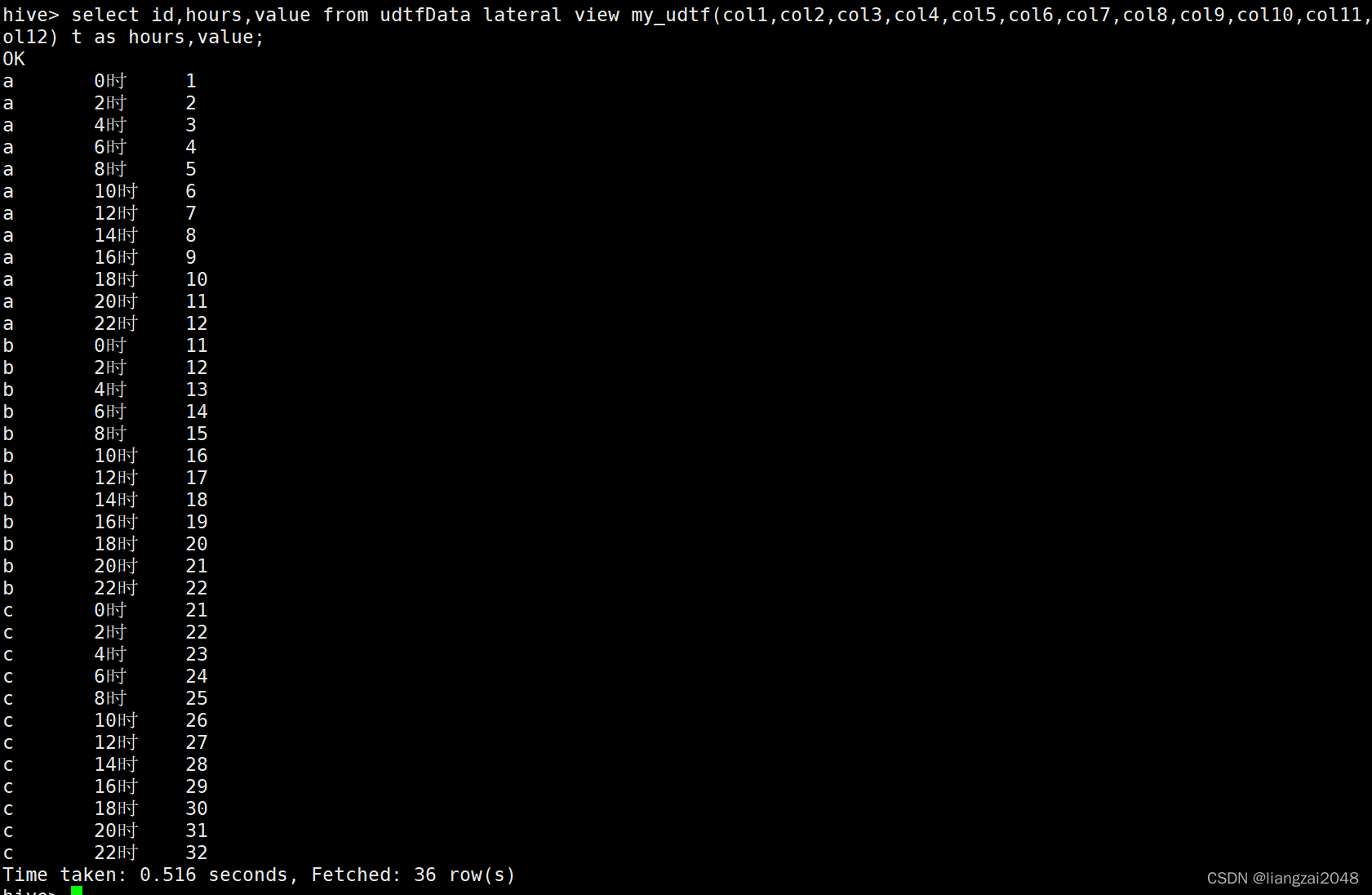
select select id,hours,value from udtfData lateral view my_udtf(col1,col2,col3,col4,col5,col6,col7,col8,col9,col10,col11,col12) t as hours,value;
到底啦!关注靓仔学习更多的大数据!( •̀ ω •́ )✧