烟台市网站建设电脑培训课程
目录
一、移除链表元素
二、删除排序链表中的重复元素
三、删除排序链表中的重复元素 ||
四、删除链表的倒数第 N 个结点
一、移除链表元素
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1: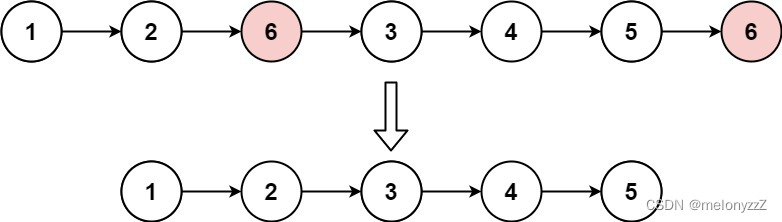
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
提示:
-
列表中的节点数目在范围
[0, 10^4]内 -
1 <= Node.val <= 50 -
0 <= val <= 50
代码实现一:
struct ListNode* removeElements(struct ListNode* head, int val)
{struct ListNode* pre = NULL;struct ListNode* cur = head;while (cur != NULL){if (cur->val == val){if (pre == NULL) // 当删除的是首元结点时,要做特殊处理,避免访问空指针{head = cur->next;free(cur);cur = head; // 切不可写成 cur = cur->next}else{pre->next = cur->next;free(cur);cur = pre->next; // 切不可写成 cur = cur->next}}else{pre = cur;cur = cur->next;}}return head;
}
free(cur); cur = cur->next是一种类似刻舟求剑的典型的错误写法。
代码实现二:
struct ListNode* removeElements(struct ListNode* head, int val)
{struct ListNode* newhead = NULL;struct ListNode* tail = NULL;struct ListNode* cur = head;while (cur != NULL){if (cur->val != val){if (newhead == NULL) // 如果新链表为空{newhead = cur;tail = cur;}else{tail->next = cur;tail = cur;}cur = cur->next;}else{struct ListNode* tmp = cur;cur = cur->next;free(tmp);}}if (tail != NULL) // 避免对空指针的解引用{tail->next = NULL; }return newhead;
}将值不是
val的结点尾插到新链表中,由于尾插需要从头指针出发顺链找到尾结点,时间复杂度高,因此可以用一个尾指针tail来记录并更新尾结点的位置。
图解示例一:

二、删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:

输入:head = [1,1,2]
输出:[1,2]
示例 2:

输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
-
链表中节点数目在范围
[0, 300]内 -
-100 <= Node.val <= 100 -
题目数据保证链表已经按升序排列
代码实现:
struct ListNode* deleteDuplicates(struct ListNode* head)
{if (head == NULL) // 判断是否为空表{return NULL;}struct ListNode* tail = head;struct ListNode* cur = head->next;while (cur != NULL){if (cur->val != tail->val){// 尾插tail->next = cur;tail = cur;cur = cur->next;}else{// 删除重复的元素struct ListNode* tmp = cur;cur = cur->next;free(tmp);}}tail->next = NULL;return head;
}三、删除排序链表中的重复元素 ||
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
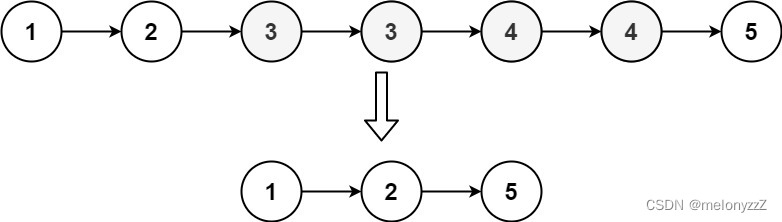
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:

输入:head = [1,1,1,2,3]
输出:[2,3]
提示:
-
链表中节点数目在范围
[0, 300]内 -
-100 <= Node.val <= 100 -
题目数据保证链表已经按升序排列
代码实现:
struct ListNode* deleteDuplicates(struct ListNode* head)
{struct ListNode* newhead = NULL;struct ListNode* tail = NULL;struct ListNode* cur = head;while (cur != NULL){// 找到第一个值不同于 cur 的结点(也可能为空)struct ListNode* after = cur->next;while (after != NULL && after->val == cur->val){after = after->next;}// 判断 cur 是否属于有重复数字的结点if (cur->next == after) // 不属于{// 尾插if (newhead == NULL) // 如果新链表为空{newhead = tail = cur;}else{tail->next = cur;tail = cur;}cur = cur->next;}else // 属于{while (cur != after){struct ListNode* tmp = cur;cur = cur->next;free(tmp);}}}if (tail != NULL){tail->next = NULL;}return newhead;
}四、删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
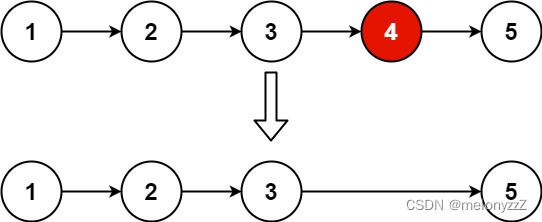
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
-
链表中结点的数目为
sz -
1 <= sz <= 30 -
0 <= Node.val <= 100 -
1 <= n <= sz
代码实现一:
struct ListNode* removeNthFromEnd(struct ListNode* head, int n)
{struct ListNode* pre_slow = NULL;struct ListNode* slow = head;struct ListNode* fast = head;while (--n){fast = fast->next; // 由于 1 <= n <= sz,所以 fast 不可能走到空}while (fast->next != NULL){pre_slow = slow;slow = slow->next;fast = fast->next;}if (pre_slow == NULL){head = slow->next;free(slow);}else{pre_slow->next = slow->next;free(slow);}return head;
}相关练习:链表的中间结点、链表中倒数第 k 个结点
代码实现二:
struct ListNode* removeNthFromEnd(struct ListNode* head, int n)
{// 设置一个哨兵位的头结点struct ListNode* guard = (struct ListNode*)malloc(sizeof(struct ListNode));guard->next = head;// 计算链表的长度(包括头结点)int len = 0;struct ListNode* cur = guard;while (cur != NULL){++len;cur = cur->next;}// 找到倒数第 n + 1 个结点(可能是 guard)struct ListNode* pre = guard;for (int i = 0; i < len - n - 1; ++i){pre = pre->next;}// 删除倒数第 n 个结点struct ListNode* tmp = pre->next;pre->next = tmp->next;free(tmp);// 删除哨兵位的头结点并返回 headhead = guard->next;free(guard);return head;
}设置哨兵位的头结点的好处是便于首元结点的处理。